Intel announced its Panther Lake mobile solution with Xe3 GPU architecture updates, building upon Xe2 and moving toward an eventual Celestial launch in the desktop GPU space
The Highlights
- Xe3 is distinct from Celestial
- We suspect that Xe3 sets the foundation for some of what Celestial will eventually get
- Intel's Panther Lake updates also include claimed power management and balancing improvements for CPU vs GPU power budget allocation in gaming scenarios
Table of Contents
- AutoTOC

Intro
Intel today is announcing its Xe3 GPU architecture to follow-up its Xe2 architecture. It’s not Celestial yet, but it’s getting close.
Editor's note: This was originally published on October 9, 2025 as a video. This content has been adapted to written format for this article and is unchanged from the original publication.
Credits
Test Lead, Host, Writing
Steve Burke
Video Editing
Mike Gaglione
Writing
Jeremy Clayton
Writing, Web Editing
Jimmy Thang

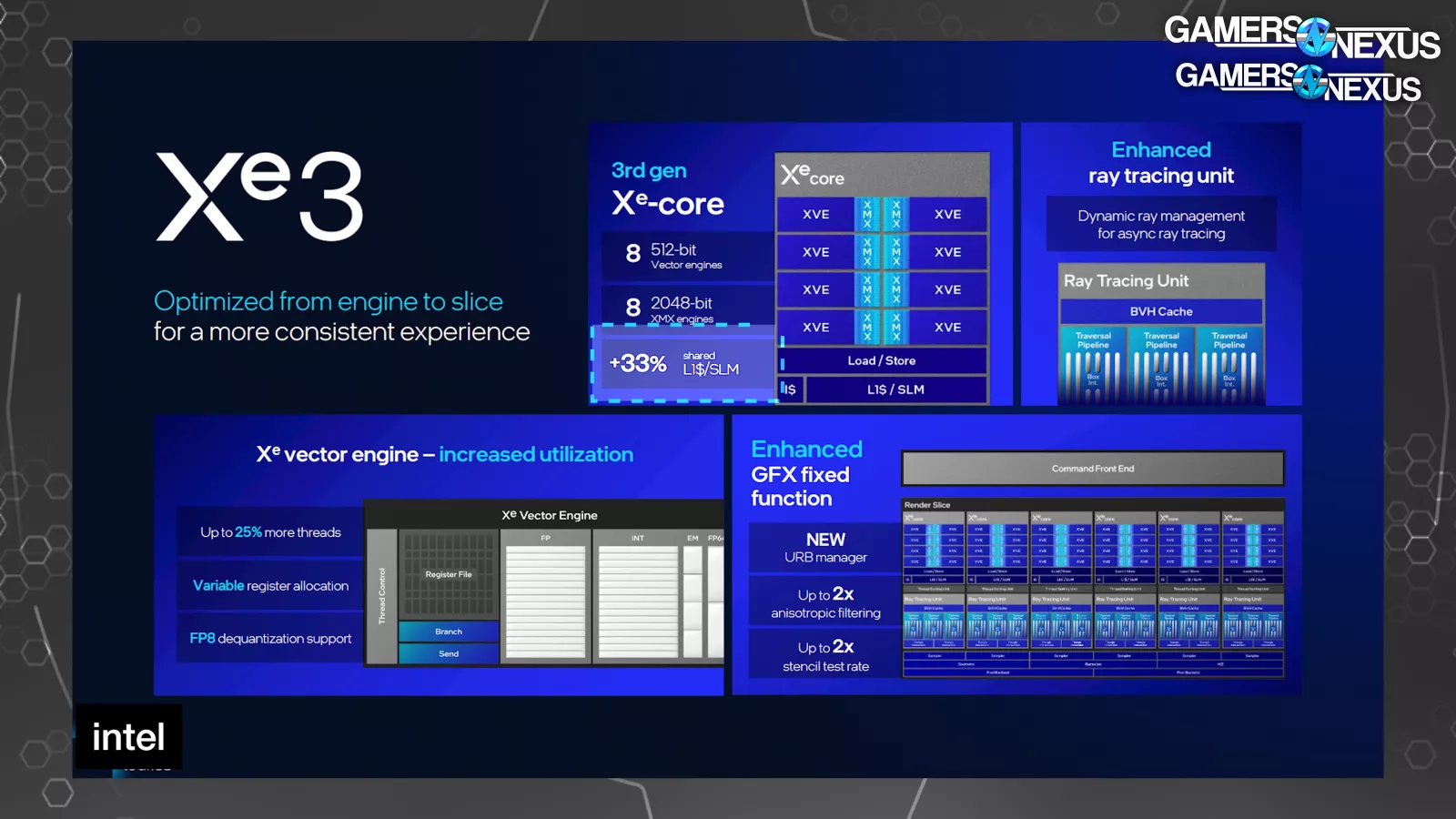
The biggest change to Xe3 is that it’s just larger, with render slices scaling up to more Xe cores per slice, an increase in L1 cache from 192KB to 256KB, a significant increase in L2 cache, and more registers that are better utilized.
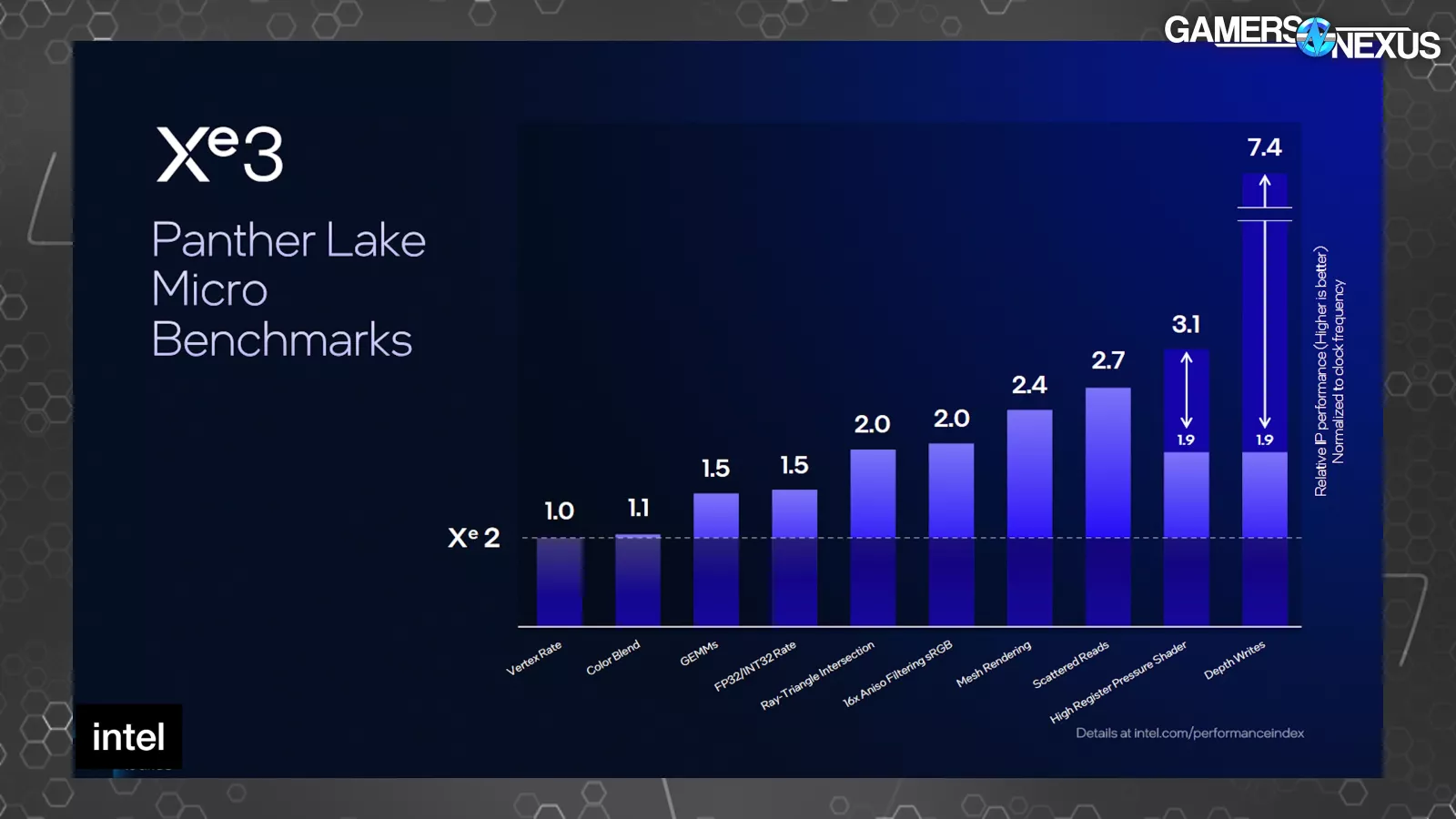
Micro benchmarks show significant improvements in occluded primitives culling for unnecessary triangles when rendering game scenes in addition to improvements in anisotropic filtering.

Its variable register allocation and register changes also aim to unclog the pipeline so that the hardware can be better utilized, as one of the biggest problems with Arc in its current Xe2 and Battlemage implementation has been that there’s plenty of hardware, but it’s not getting used properly. This is a mix of both hardware issues, like with fixed function units in the architecture, and driver issues, which it has been slowly addressing. Some of this included moving off of emulation of things like execute indirect previously to eliminate overhead.
For Xe3, Intel noted to us some of its driver improvements and software control panel focus as well, all of which should benefit the company as it moves toward its eventual dGPU Celestial GPUs.
This accompanies a number of other announcements related to its Panther Lake mobile solutions and laptop hardware, plus some “AI” and NPU hardware.
We’re mostly going to focus on the IP block of Xe3 and the architecture and won’t be as focused on the product side for laptops.
Although this isn’t a dGPU part, it’s likely that this approach will either be directly found in the next dGPU or will at least indicate which direction Intel is going.
Intel was clear that this isn’t exactly Celestial, which is the architecture following in the Alchemist - Battlemage - Celestial - Druid lineup. Intel noted that “Xe3P” will follow Xe3. The “P” unironically stands for “Plus,” showing old Intel habits die hard. Intel didn’t confirm this, but the impression we got is that Xe3P will be the “real” Celestial GPUs, while this Xe3 makes major changes that likely set the stage for it.
Overview of Announcements
Intel had a lot of announcements to share with the press for today. For our coverage, we’re focusing almost entirely on the Xe3 changes and micro benchmarks. We’ll cover some of the other news as well, like performance/Watt improvements and XeSS changes, but we’re not going to get into the NPU and AI processing changes today. There’s enough to talk about just with the stuff that’ll affect consumer desktop components in the future (plus the immediate impact to laptops).
All of this follows the announcement that NVIDIA is investing in Intel to build its own mobile parts with them later, but there’s no news on that topic today. This is all Intel’s hardware.
Naming Confusion
Briefly on the naming: Intel admitted its naming mix of Xe for IP and Alchemist / Battlemage / Celestial / Druid for branding has been confusing. It was careful to note that these parts are not Celestial and the impression we got was that they don’t want to burn the name on an incremental improvement prior to a pending major overhaul. Intel is sticking with “Arc B-Series” for the Panther Lake mobile parts, but is moving to the Xe3 architecture. Xe3P will likely be Celestial or desktop parts later.
Xe3 IP GPU Block
Intel specifically mentioned designing Xe3 to scale to larger configuration sizes, which would be good news for anyone who wants to see something higher-end than a B580-class card in the future.
Let’s get into micro benchmarks first, then look at the block diagram.
This is a chart of micro benchmarks, which are workloads designed to target extremely specific functions or behaviors on a product. A 2x improvement here won’t equal a 2x improvement in most real-world applications, but these allow us to see where the improvements are appearing. Intel published these for Xe2 also.
In Xe3 for “depth writes,” Intel says it saw a 7.4x relative performance improvement normalized to clock frequency. We’re not certain, but our understanding is that this is not isolated for configuration size. This means that this isn’t a perfect comparison since the Xe core count is different between Xe2 and Xe3 in these tests. This 7.4x improvement outstrips the change in configuration size, though.
We asked Intel what “depth writes” means. The company told us that it’s related to high-Z culling and that this bar represents better primitives culling in the pipeline, meaning culling of unseen triangles and geometry sooner in the pipeline so as not to waste resources rendering unseen objects in-game. An example might be if a building is obstructing a player -- there’s no point rendering the player if it can’t be seen. Culling isn’t new and batching primitives in ways that eliminate occluded primitives has been around forever, but this shows that there’s still plenty of ground to gain here for Intel. This will result in better utilization of resources and allocating them to more productive work. Intel told us that the improvement to this process is disproportionately beneficial, meaning that it should have an impact in gaming performance that would be more noticeable than other improvements. We’d expect this to carry over to future Celestial dGPU parts as well.
The “High Register Pressure Shader” section also saw a large uplift in micro benchmarks at 1.9x to 3.1x. Scattered reads improved by 2.7x on the relative scale of time, with Intel noting to us that this has to do with using samplers to read data scattered across something like a texture (as opposed to a well-organized data set).
Mesh rendering is also shown here, with Intel telling us that Xe2 had already provided a proof of concept around improving mesh shading. Intel noted that this micro benchmark is representative of workloads where a lot of polygons are present, telling us that the uplift comes from a larger cache and more efficient use of its registers. Culling also contributes.
Quickly, Intel also saw uplift in anisotropic filtering, which is the old function that helps improve smoothness of textures and objects proportionate to the view frustum’s angle. Ray-Triangle intersection also improved by 2x in the microbenchmarks on the relative scale, which is noteworthy since Xe2 already benefitted from relatively large ray tracing improvements.
Looking back at the Xe2 micro benchmarks, Intel then highlighted Draw XI and Compute Dispatch XI primarily. At the time it talked to us about this chart, Intel told us that this was due to implementation of native execute indirect support for indirect draw and dispatch, as opposed to its Xe1 emulation of these functions.
Block Diagram

Time to get into block diagrams for how the new Panther Lake Xe3 block is constructed. This shows a 12 Xe-core configuration as the maximum size announced for mobile, with this configuration carrying 16MB of L2 cache, 2 geometry pipelines, 12 samplers, and 4 pixel backends. The L2 cache is noteworthy here.

This is the new Xe3 render slice. A render slice is Intel’s terminology that defines a block on the GPU containing Xe cores. For reference, the Battlemage B580 with Xe2 has 20 Xe cores on 5 render slices, so each slice is just one part of the total GPU.
The Xe2 slice had 4 Xe cores each, with Xe3 moving to 6 Xe cores per render slice. Intel also intends to scale-up the configuration size on mobile devices to a maximum of 12 Xe cores (or 2x render slices, up from 8 Xe cores on a prior 2-slice configuration).
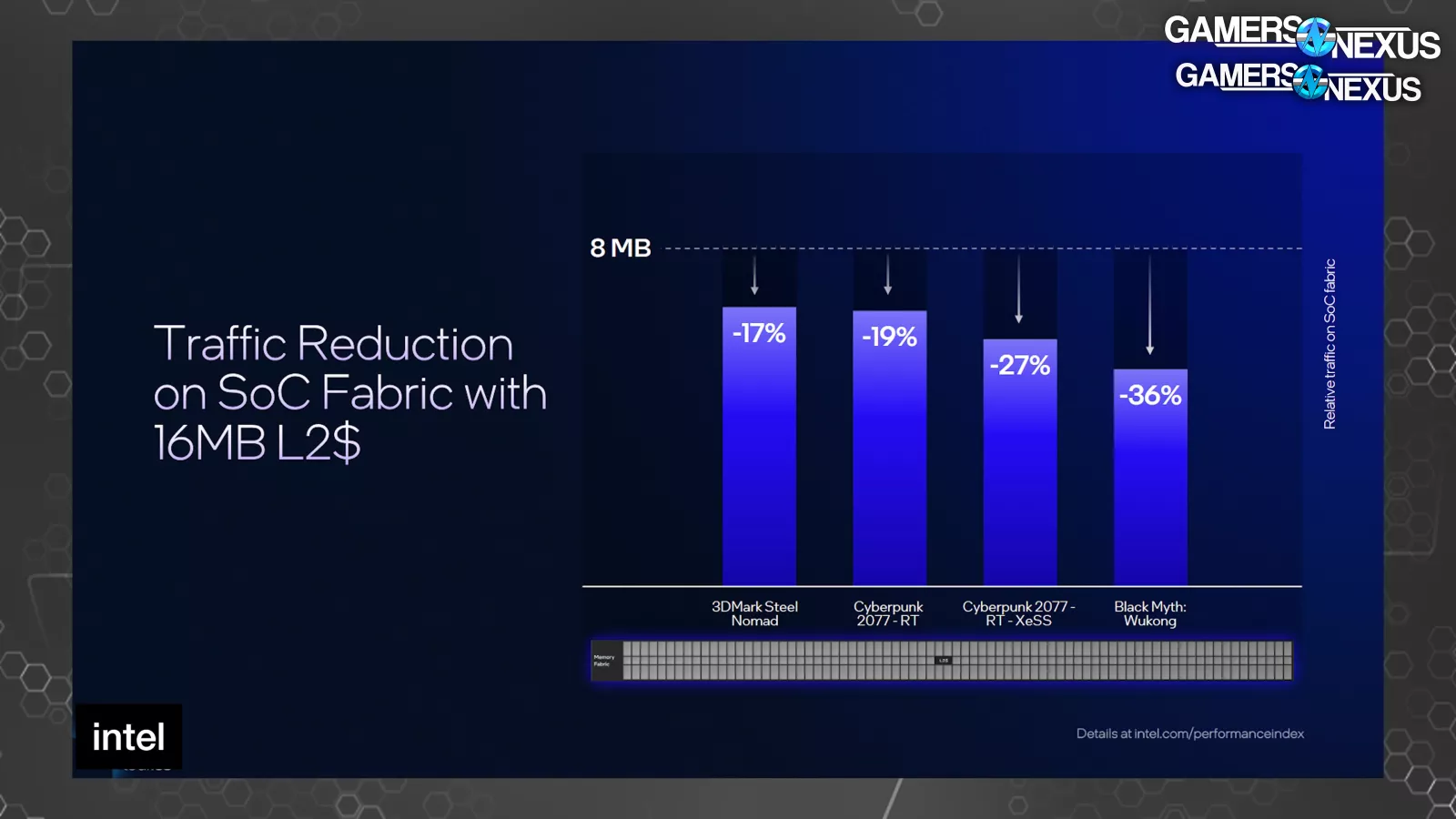
The Xe3 render slice shows that each Xe core has 8 vector engines, which is unchanged from Xe2 cores; however, Intel is increasing the cache size in Xe3. Intel’s Tom Petersen stated, “The first thing we’ve done is increase the size of our L2. By increasing the size of the L2 from 8MB to 16MB, we reduced the traffic that hits the memory interface. That’s important because the memory interface is typically one of the most precious resources on a graphics chip. We can see anywhere between 17% and 36% traffic reduction heading towards memory, which has a significant performance effect on these different applications.”
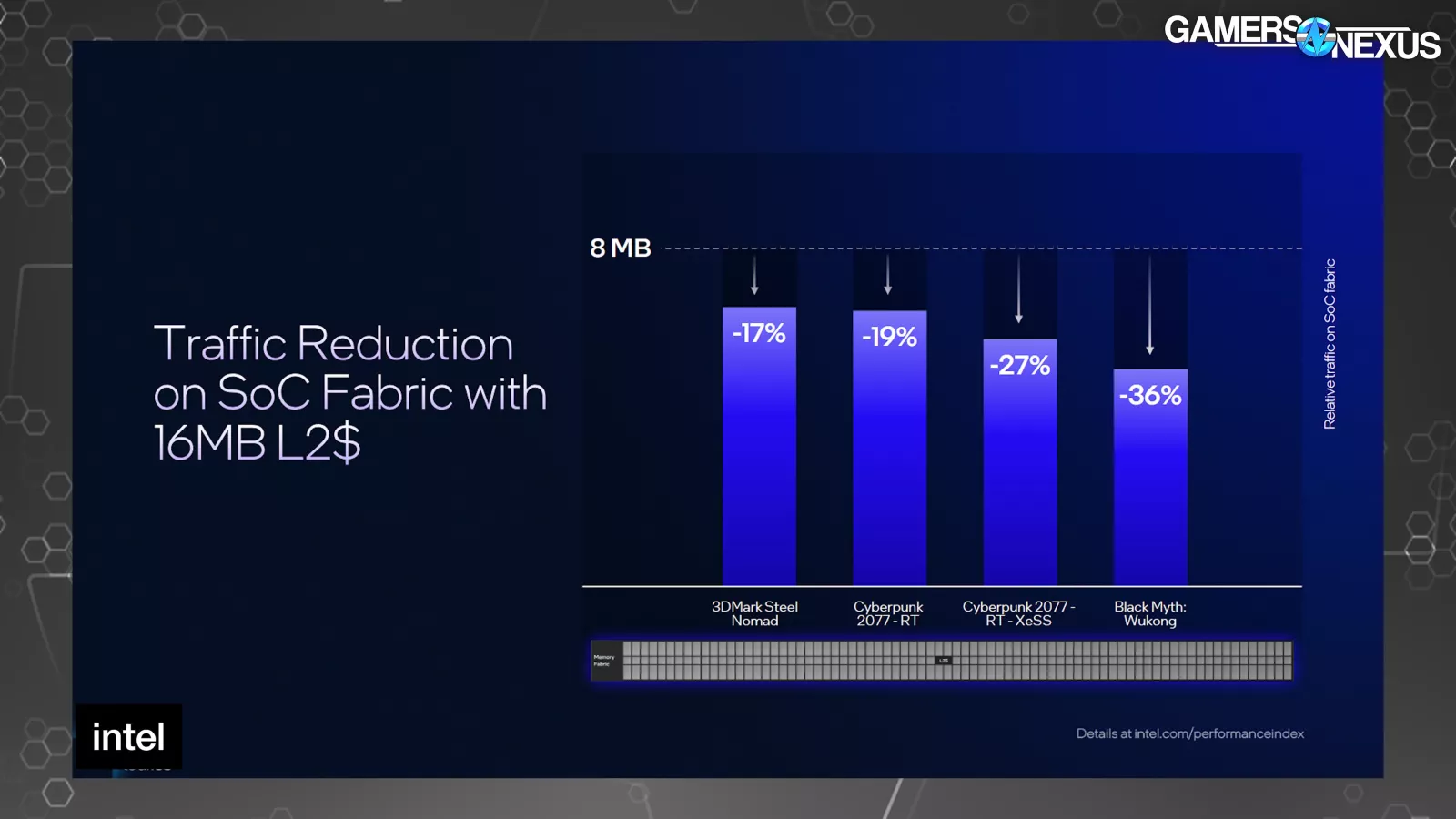
Looking at Intel’s first-party results, it presents the improvement in the form of relative traffic on the SoC fabric (in the vertical axis) against a baseline 8MB L2 cache. Cyberpunk with RT showed a 19% reduction, Black Myth rasterized showed a 36% reduction, and the rasterized Steel Nomad test showed a 17% reduction.

Intel also told us that it has increased its L1 Cache by 33%, noting a move from 192KB to 256KB. When we asked Tom Petersen which area of uplift he thought had the most impact on overall performance, he pointed us toward the register and thread changes. Intel has increased thread count upwards of 25% depending on configuration and has moved to variable register allocation. Petersen noted that occupancy of the compute units (including on Battlemage) previously wasn’t always high, despite them being available for work, meaning that there was more GPU hardware present than was being properly utilized by applications. Intel has focused on this in both drivers and hardware. He noted that previous register allocation and thread count choices would “starve the pipeline if the shader used too many registers,” which is being addressed.

The ray tracing unit also got improvements. Intel says it “slowed down dispatches of new rays while the sorting unit catches up,” citing out-of-order dispatch and triangle testing. The ray tracing unit improvements seem to be largely attributed to asynchronous dispatch-test processes.

Intel also highlighted a new URB manager as part of its fixed function enhancements, which is also where we find the anisotropic filtering uplift. Petersen stated this, “We also now have a new URB manager, which allows partial updates versus flushing the whole thing. Our URB is a structure where we pass results between our units inside of our GPU. It used to be somewhat of a serializing point; now we can actually use that partially without flushing each complex.”
Frame Inspection

We thought these next couple slides were pretty interesting as well:
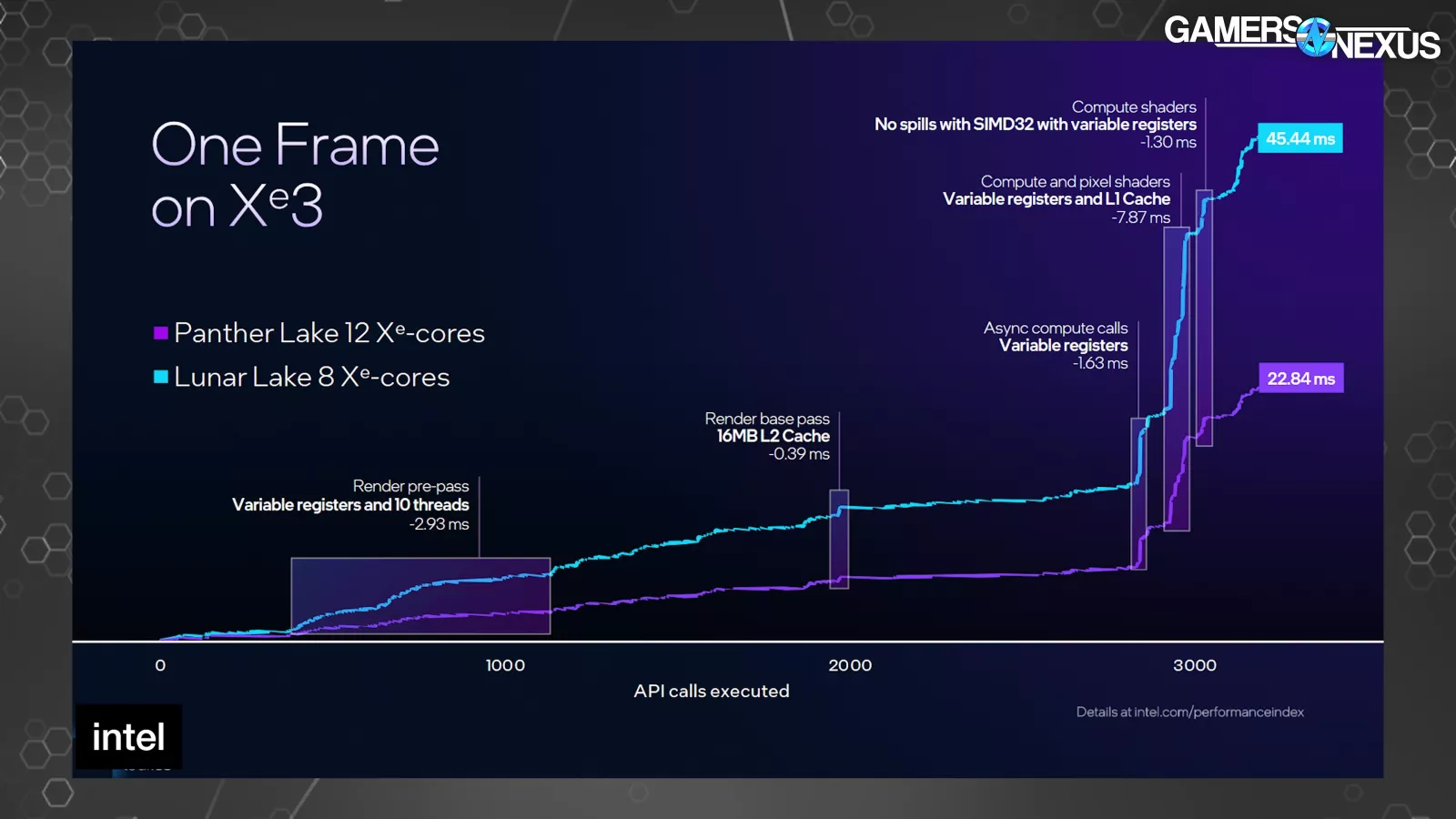
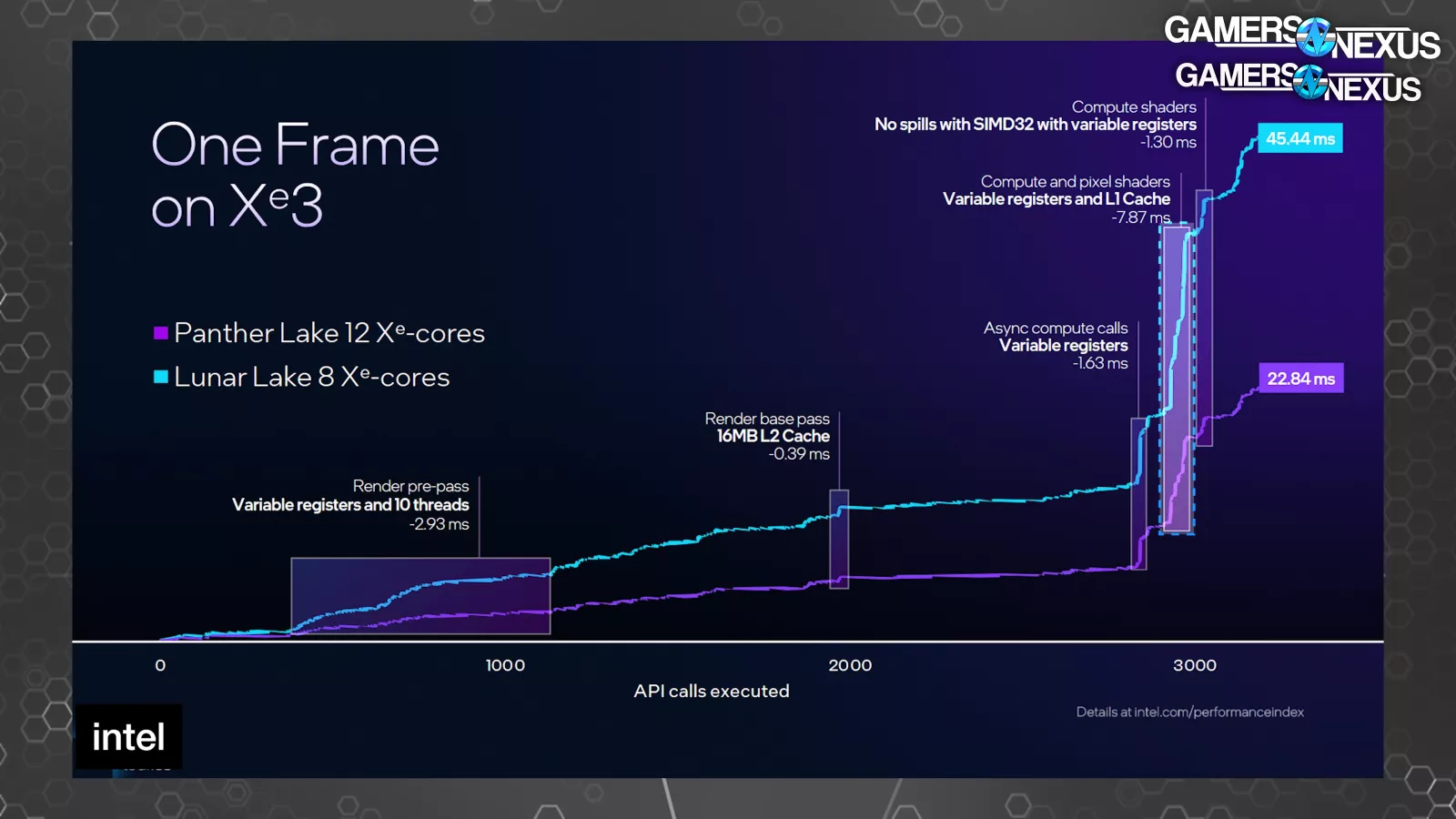
Intel showed a frame on Xe3 versus Xe2. These are not normalized for configuration size, so it’s not a perfect comparison and it shows a 12-core vs. 8-core configuration, disallowing a perfect like-for-like inspection. This is iso frequency and power, so it is at least normalized there.
The horizontal axis is for API call execution, with the vertical axis being milliseconds of time to execute across a single frame being drawn (higher is worse). This is for Cyberpunk 2077.
Of note, Intel shows an 8ms reduction to Xe3 with the compute and pixel shader section toward the end, assigning some of that uplift to the change to the variable registers and L1 cache size increase. We can also see that, according to Intel, the L2 benefits the render base pass with a 0.39ms improvement, preceded by the move to 10 threads (and variable registers) providing a 2.93ms improvement in the pre-pass.
More broadly, Petersen told us in a call that the register allocation and number of threads would starve the pipeline if the shader used too many registers previously, which is being partially addressed here. He said that the previous architecture could cause a reduction in the utilization of available compute resources due to regular flushing of the pipeline due to regular reallocation into memory.
This image is pretty cool and is a look at what actually happens in a frame when it’s being drawn. We have a full video talking about this previously.
Power Delivery

Intel’s focus on power delivery and power management cites learnings from the MSI Claw (read our review) devices and mostly comes in the form of ensuring proper resource allocation for power budget between the CPU and GPU, which should benefit laptop and handheld devices that have a limited power budget split between the two.

Intel noted that previously, a lack of application awareness meant that the device could sometimes divert too much power to the CPU, leaving the GPU bottlenecked on its power limit while the CPU offered a level of performance that wasn’t being kept-up with by the GPU.

Intel gave the MSI Claw as an example of a time this didn’t go well.
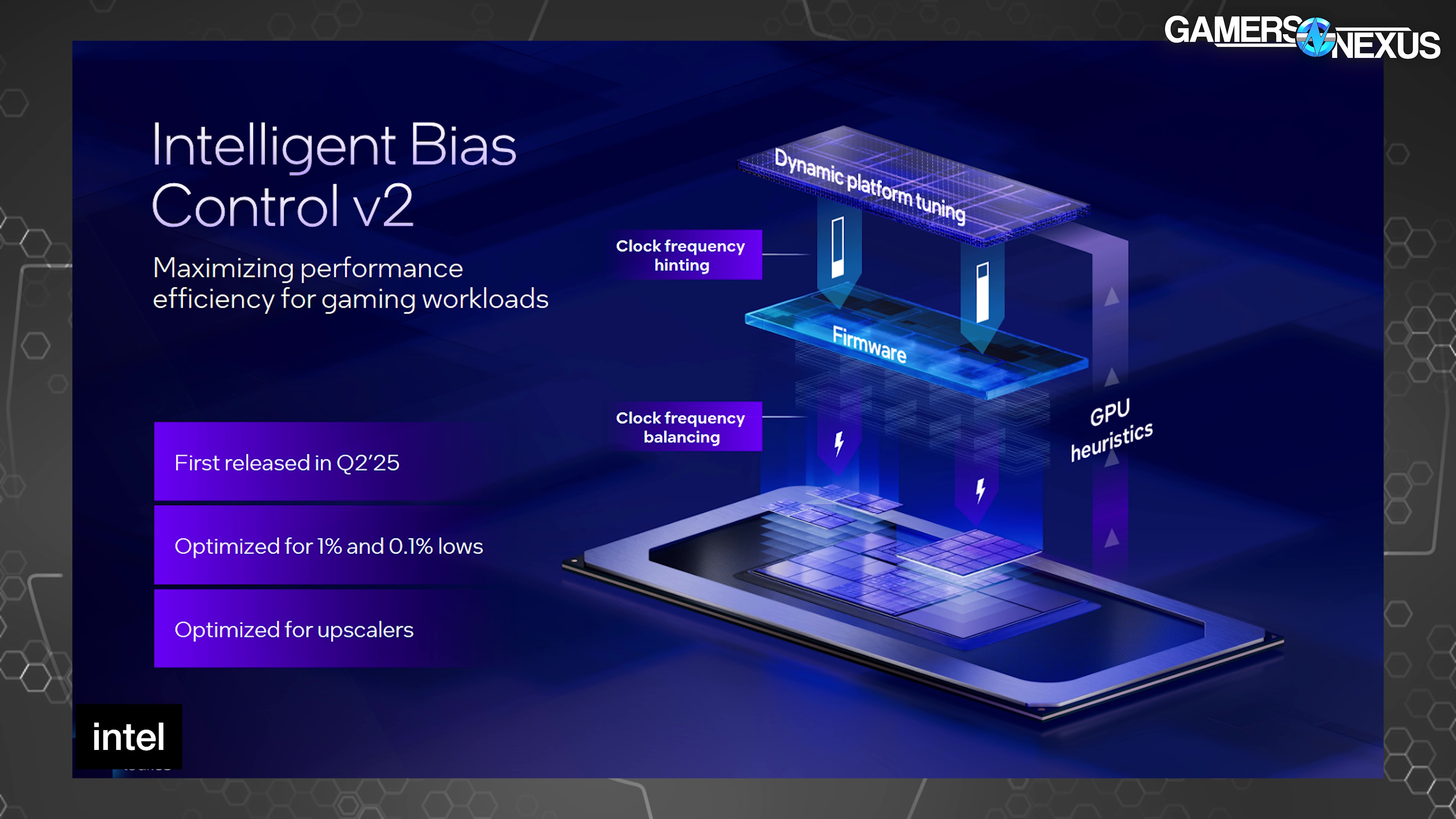
The company noted that it improved on this earlier in the year with its Intelligent Bias Control v2 and is now introducing a v3 to build upon that.
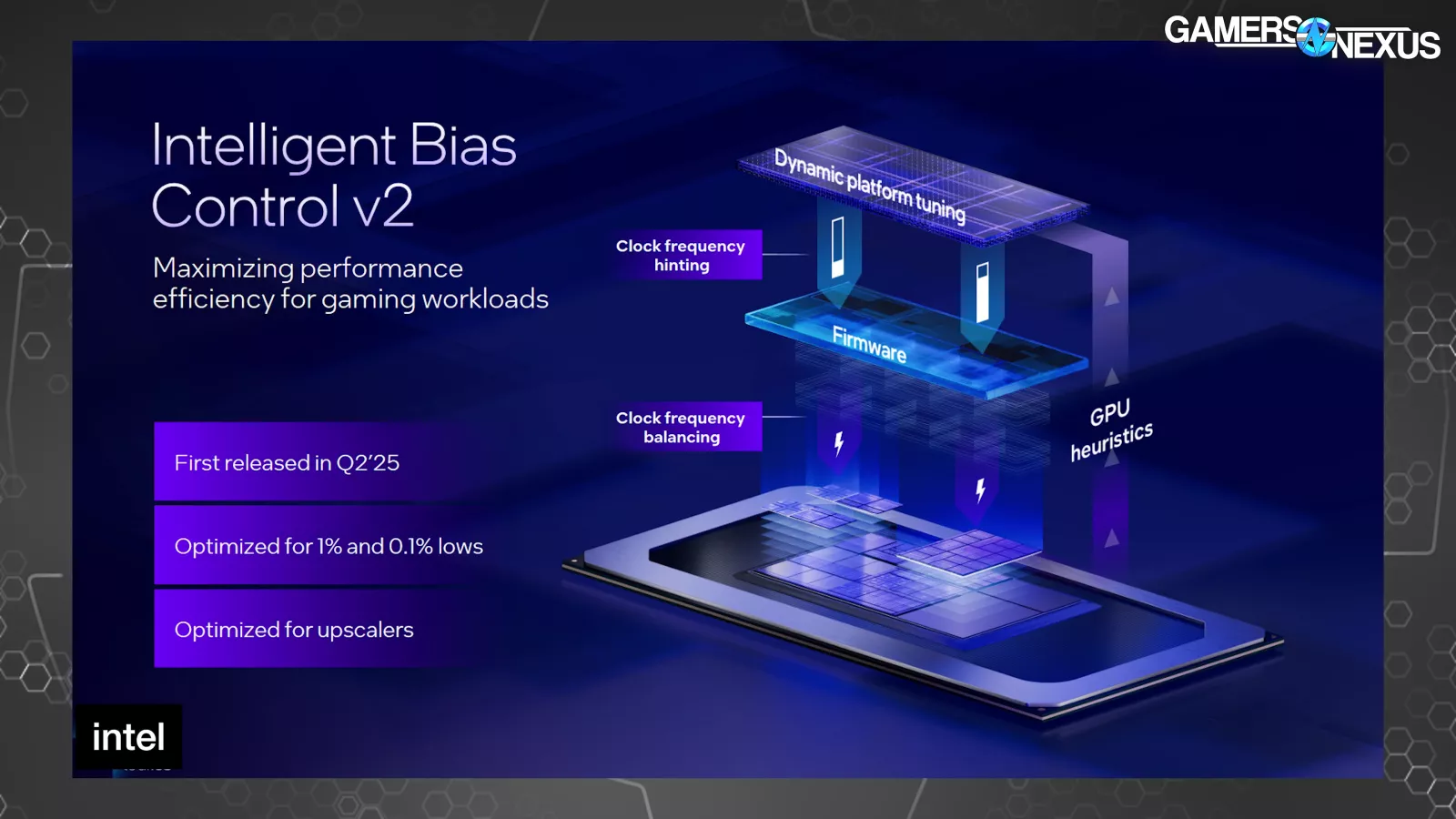
Because the system was previously unaware of the application being run, in this case a game, Intel said that software and hardware wouldn’t correctly balance the workload between the CPU and GPU, resulting in stuttering due to being power starved.
“Intelligent Bias Control v2” took GPU heuristics and utilization metrics to then inform thread scheduling and resource assignment at the operating system-level. Intel had previously marketed improvements to 1% and 0.1% low metrics via better frame interval pacing as a result of this change.
The new v3 version of this adds E-core first scheduling, which is self-explanatory in that E-cores get scheduling first when gaming. This sounds worse, and typically would be, but Intel says that the end result is reduced power diversion to the CPU by using lower power cores prior to P-cores, freeing-up more of the shared total power budget to go toward the GPU instead. In GPU-bound scenarios, like many games particularly on handheld devices, this is a better outcome than burning power on a component that isn’t as burdened.

This comparison between Panther Lake and the prior generation of this bias control solution shows that peaks in power utilization have smoothed-out while the GPU power consumption has leveled to be more predictable. Reminder: This is a first-party tests. The GPU is also getting more total power budget as a percentage than previously, while reducing CPU power in exchange. For GPU-bound scenarios in particular, this should be a better outcome. It might help in some CPU-bound scenarios as well.
XeSS Multi-Frame Generation and Other Changes
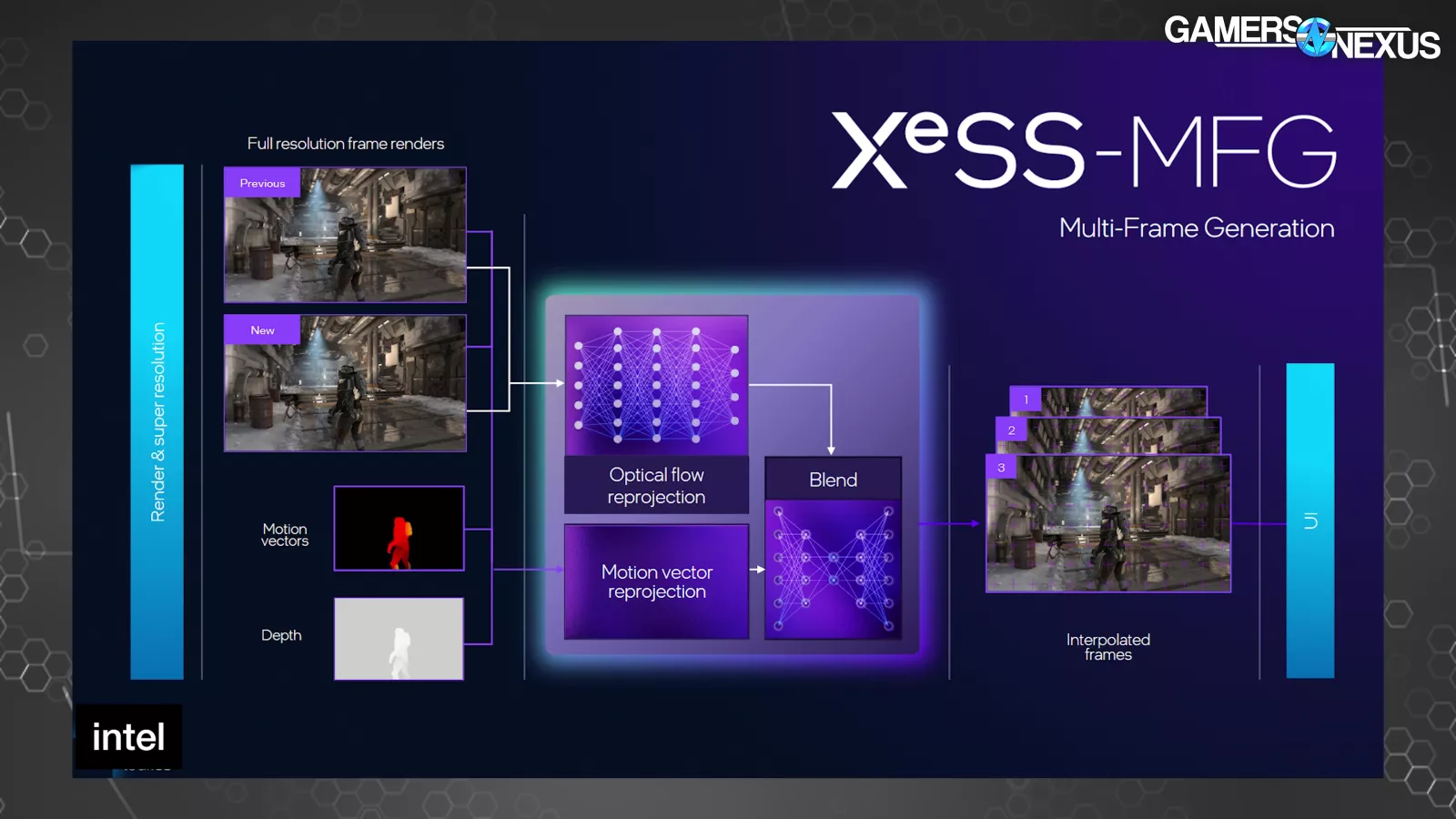
Intel also announced XeSS 3, which includes XeSS-Multi-Frame Generation (or XeSS-MFG). A few more letters and they’ll have the whole alphabet.
XeSS-MFG is conceptually similar to NVIDIA’s MFG. XeSS-MFG takes 2 real frames to calculate optical flow networks using motion vectors and the depth buffer, then uses that information to generate up to 3 frames between the 2 real frames. The frames are then displayed in order and paced in a way to minimize animation error. We also have a separate deep-dive on our new animation error testing methodology.
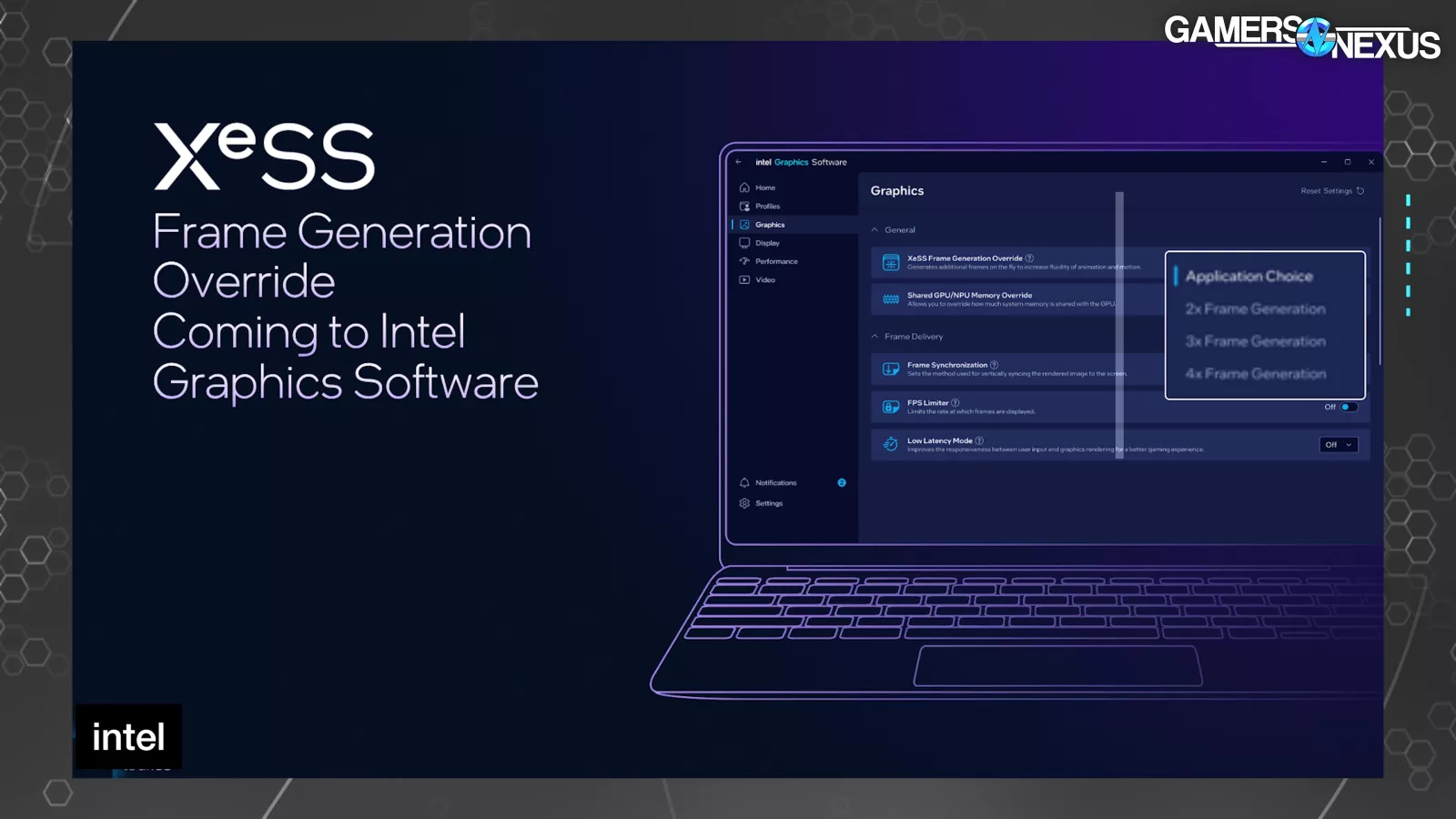
The new “XeSS Frame Generation Override” setting in the driver software allows the user to set 2x, 3x, or 4x mode.
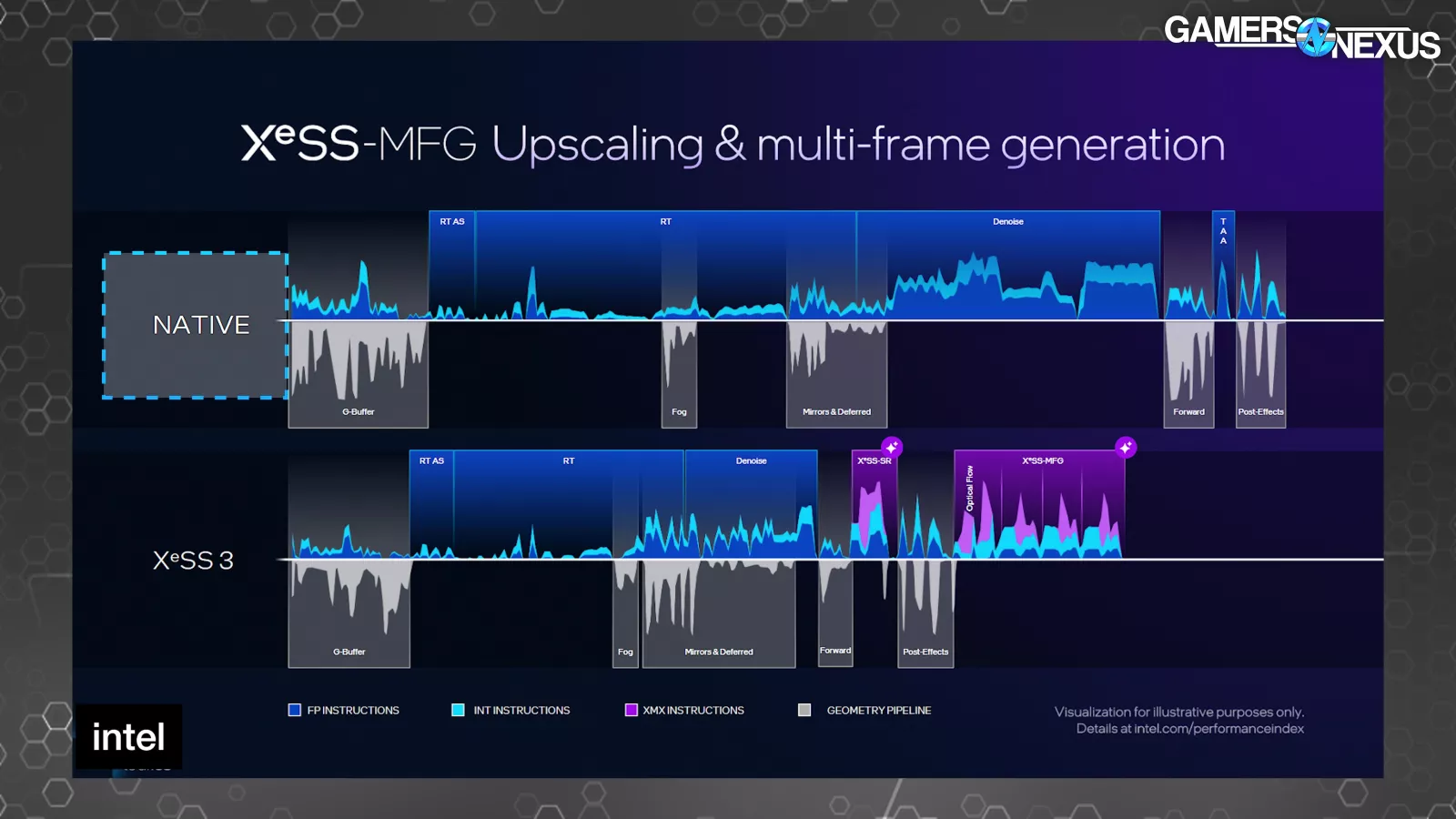
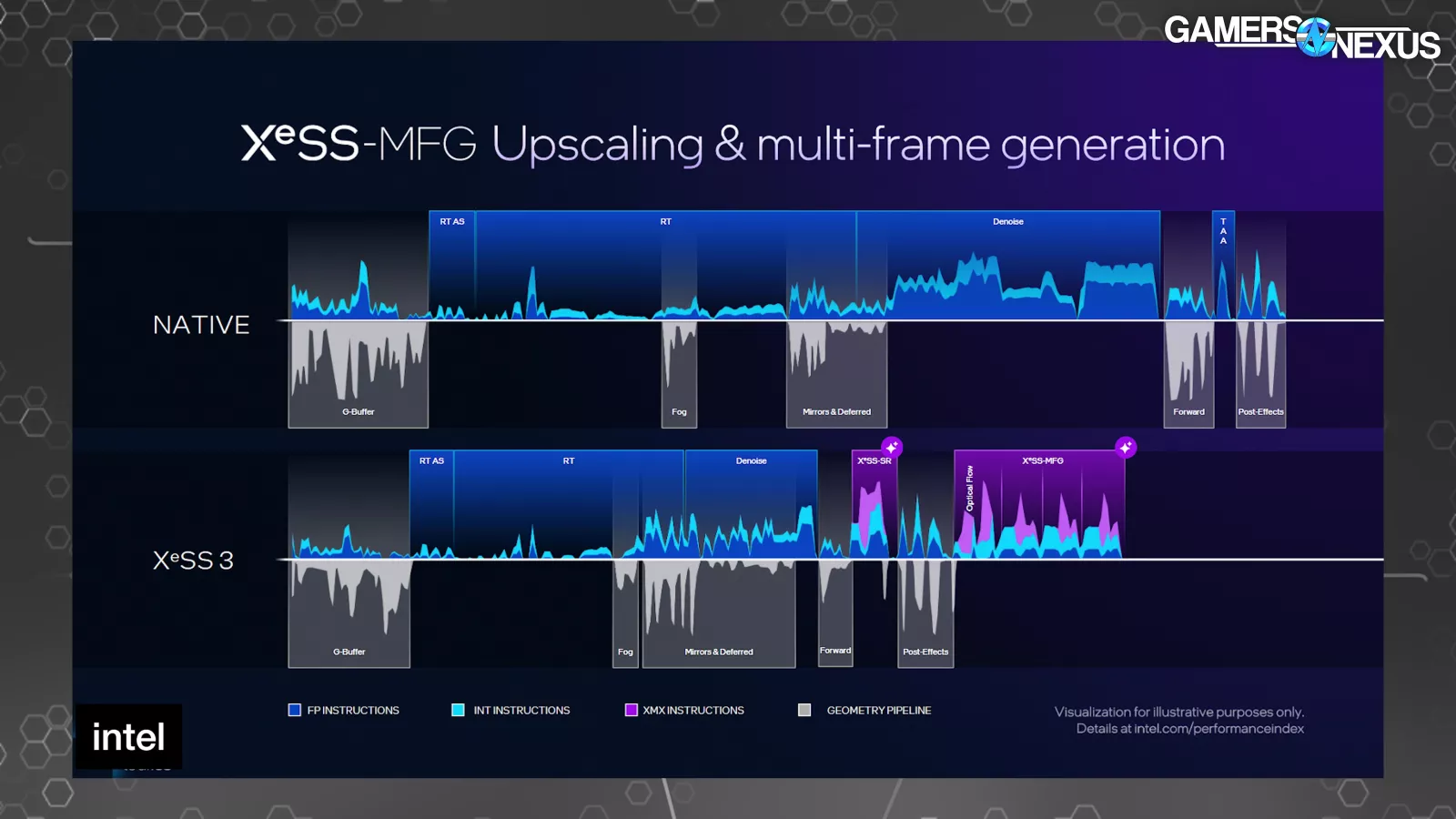
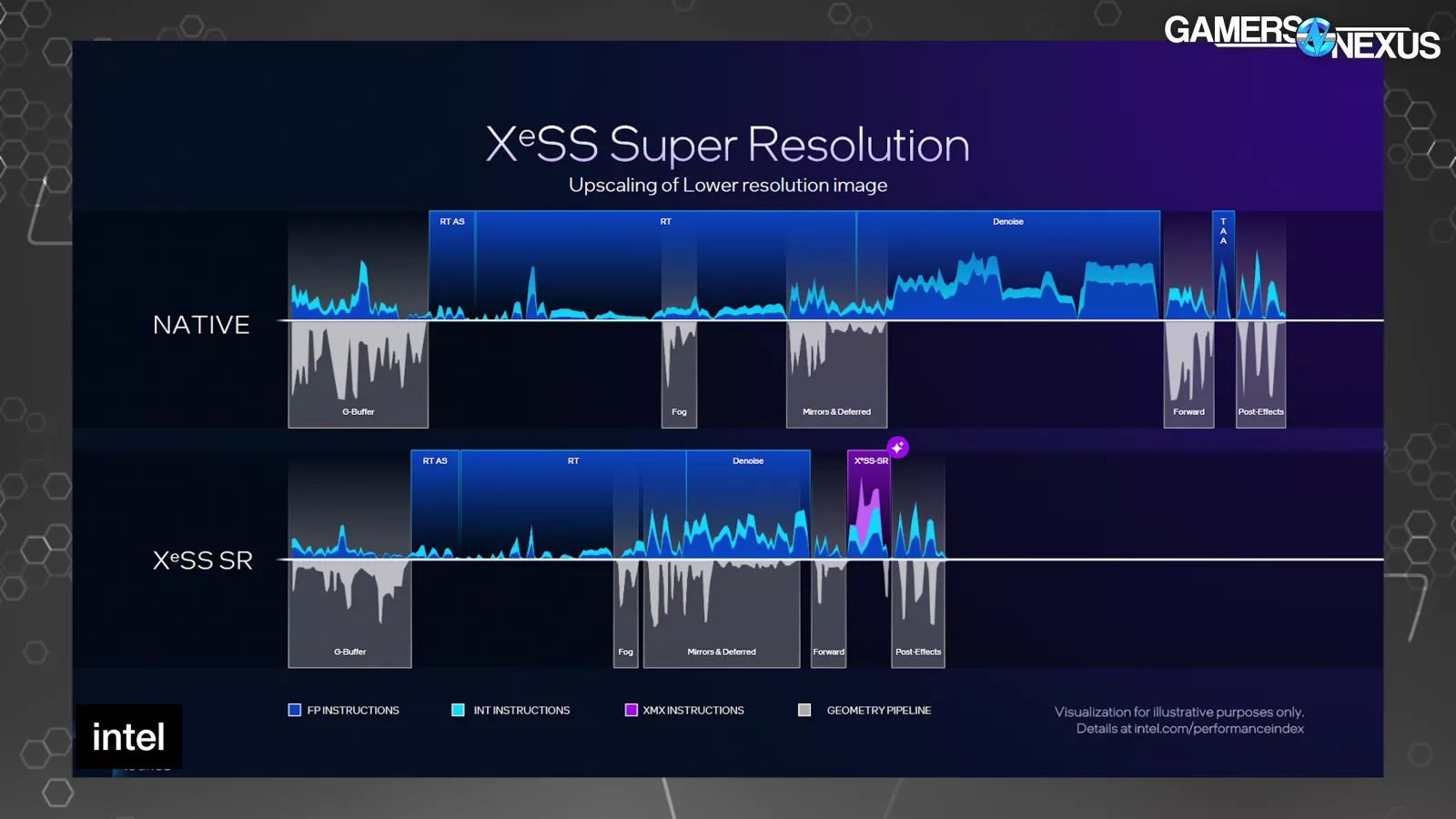
Intel presented a few timelines of a single frame. One at native, and then several with various levels of XeSS technology in use. The shorter the duration that the frame is on the X-axis, the less time the frame took to complete. The top half of each shows instructions and the bottom half shows when the geometry pipeline is active.
Compared to native, the raster, RT, and denoise sections of the frame are shorter on the XeSS 3 timeline due to rendering at a lower resolution. The first purple section represents XeSS-SR to perform the upscaling. The second purple block starts with the optical flow portion of frame gen, followed by 3 frame generation operations.

It seems like Intel’s argument is that the entire frame gen process takes less time than drawing one real frame, and is therefore better or something, but this totally ignores image quality. We’ve shown with both AMD FMF and NVIDIA MFG that the image quality sacrifice isn’t always worth it. Sometimes it is, but it’s not always as simple as being that way. Intel stated that these frames upscaled with XeSS-SR are the same quality as native, which is unlikely. Intel stated: “That frame is as good as the prior picture, the native frame. But it’s actually being run quicker.” We doubt this will be broadly true and will evaluate later on dGPUs. It was bullshit when NVIDIA claimed it, too. The quality can be good, but is rarely as good.
Intel had some other side-by-sides that we take issue with, and that in combination with still having watermarks on the video means we’ll skip them and just test it ourselves later.
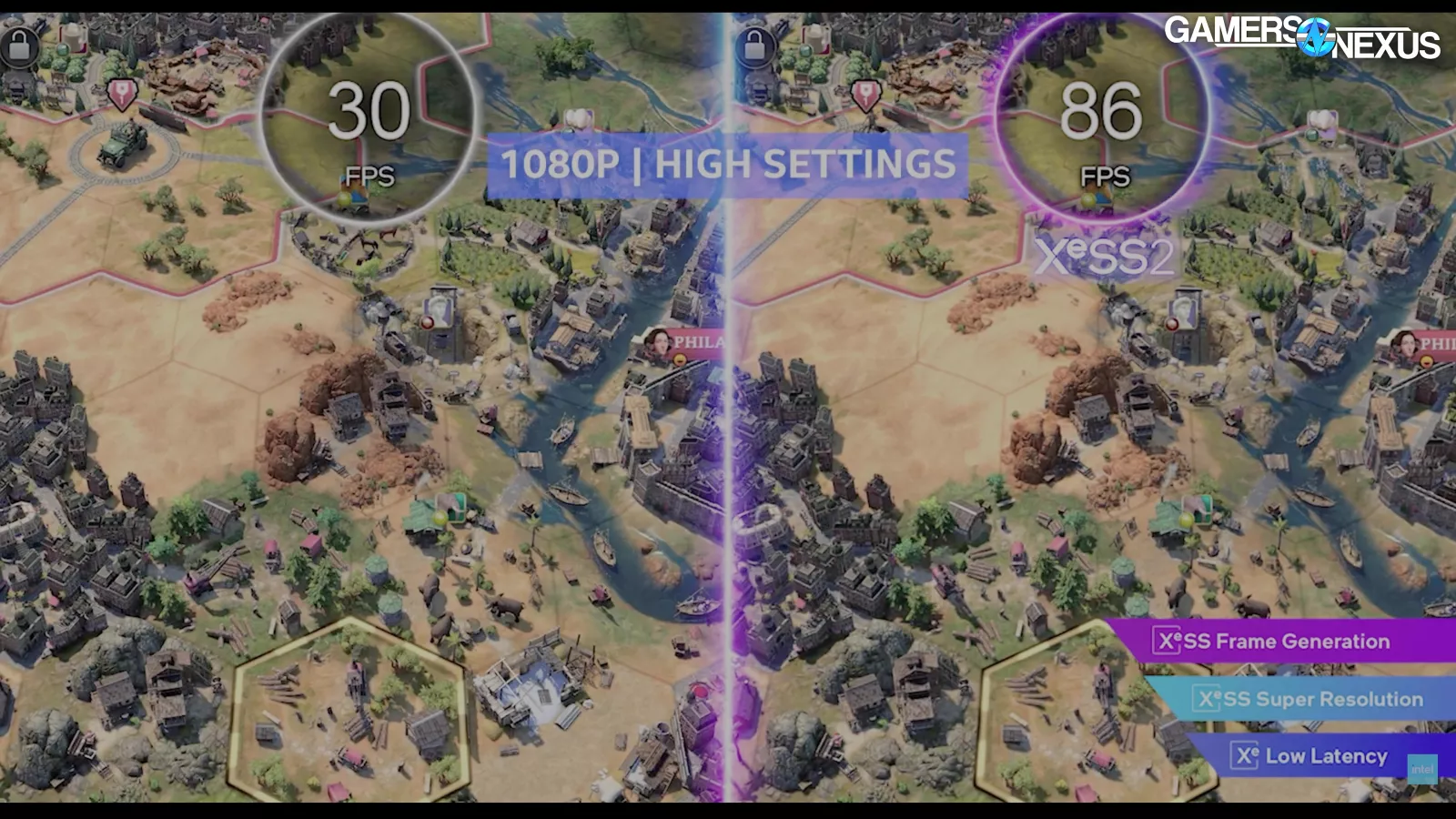
Intel referred to the frame gen process as looking into the future. NVIDIA CEO Jensen Huang has said similar things about NVIDIA’s frame generation. Both of them are wrong, because all current methods of frame generation rely entirely on finished frames and engine data. These frames already existed and could have been displayed instead of holding them to run the frame generation in between. That isn’t looking into the future, that’s interpolating between two sequential snapshots of the present or near present. Until a predictive method of frame generation comes out, none of these technologies look into or generate “the future,” they at best interpolate the past. And that’s fine, but we’d really like it if these companies could get their shit together and stop saying that they generate the future.
MFG represented on benchmark charts has been a major and ongoing controversy and misrepresentation of performance on NVIDIA’s side of things. Intel committed to relying on base raster performance without frame generation as the baseline for performance and said that, when it publishes numbers including upscaling or frame gen, those will be provided as supplemental to the base metric. We think this is a better balance of promoting the capability without totally misrepresenting the reality.
Intel also talked about a new version of PresentMon that includes a few changes, partly accounting for frame generation technology.