
Intel shared Battlemage GPU and Lunar Lake CPU technology details at Computex 2024.
The Highlights
- New Intel GPU and CPU Microarchitectures Detailed
- Battlemage GPUs will still need robust driver support
- Intel is ditching Hyper-Threading on P-cores

Intel has official Battlemage information for its next GPU architecture. Pictured below is one of the first motherboards with Xe2 on it, which is what’s going into Battlemage in discrete GPUs for desktop later. This board was stealthily handed to us to show an upcoming Intel Lunar Lake integration in a future laptop motherboard, and even though it’s mobile silicon, it still features the architecture that’ll build Intel’s next desktop GPUs.
Editor's note: This was originally published on June 3, 2024 as a video. This content has been adapted to written format for this article and is unchanged from the original publication.
Credits
Host, Writing
Steve Burke
Writing, Web Editing
Jeremy Clayton
Video Production
Mike Gaglione, Vitalii Makhnovets

Battlemage GPU Architecture
Intel unveiled the basics of its Battlemage GPU architecture at Computex this past week alongside details of its upcoming Lunar Lake lineup. Instead of covering Intel’s keynote, we’re focusing this video on a series of engineering pre-briefings we had. That includes discussion of Battlemage as hosted by Intel’s Tom Petersen, but also some early core architecture details. On the CPU core architecture side, the biggest change is that Intel is ditching Hyper-Threading. We don’t have everything today, but enough of an architecture detailing to get started.

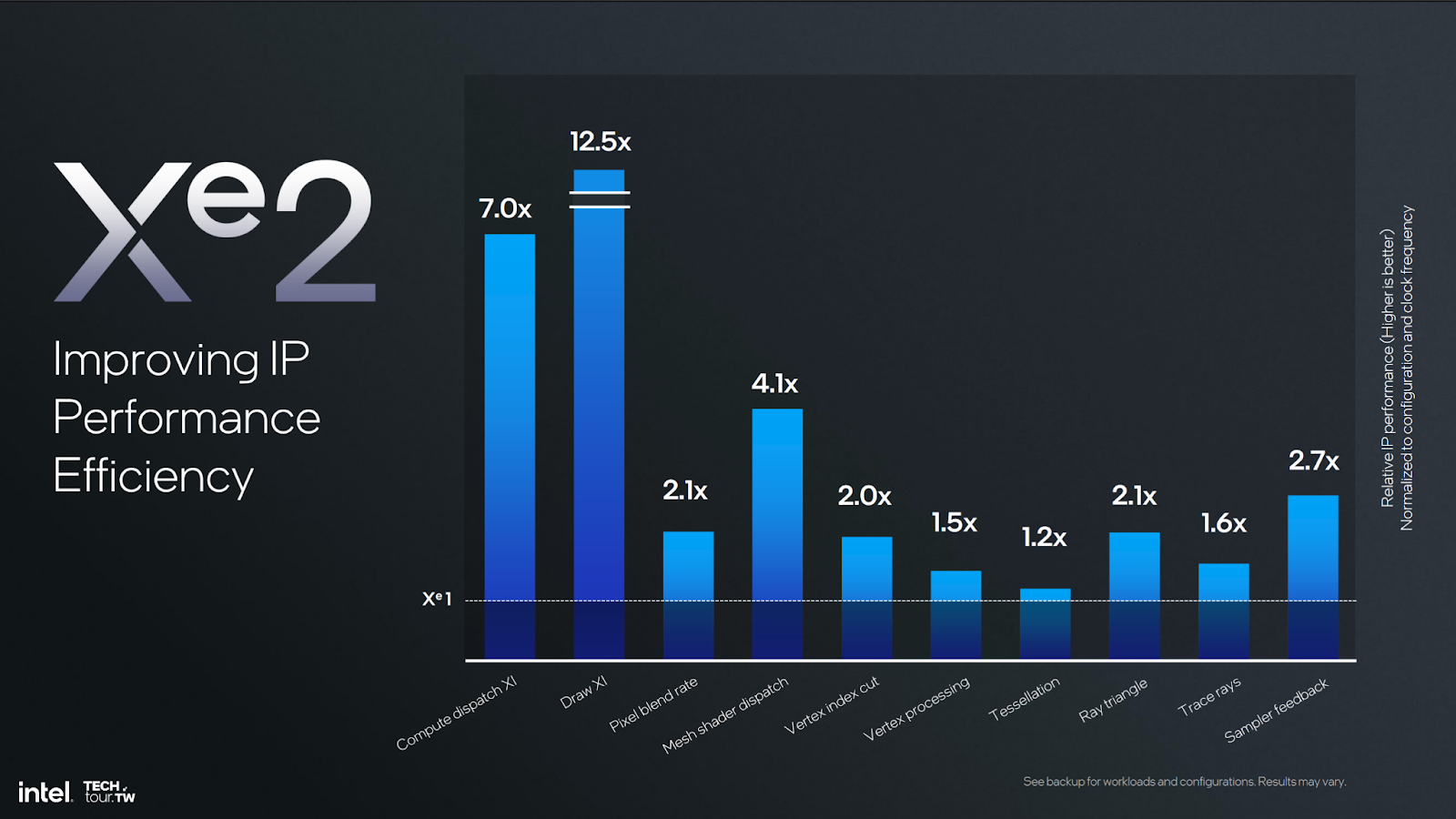
Intel showed some charts with clock-normalized uplift against specific functions of the GPU, like a 12.5x relative increase in Draw XI, 2.1x normalized increase in pixel blend rate which comes from some changes we’ll cover today, a 4.1x mesh shader dispatch improvement, and some lesser areas of uplift like tessellation.
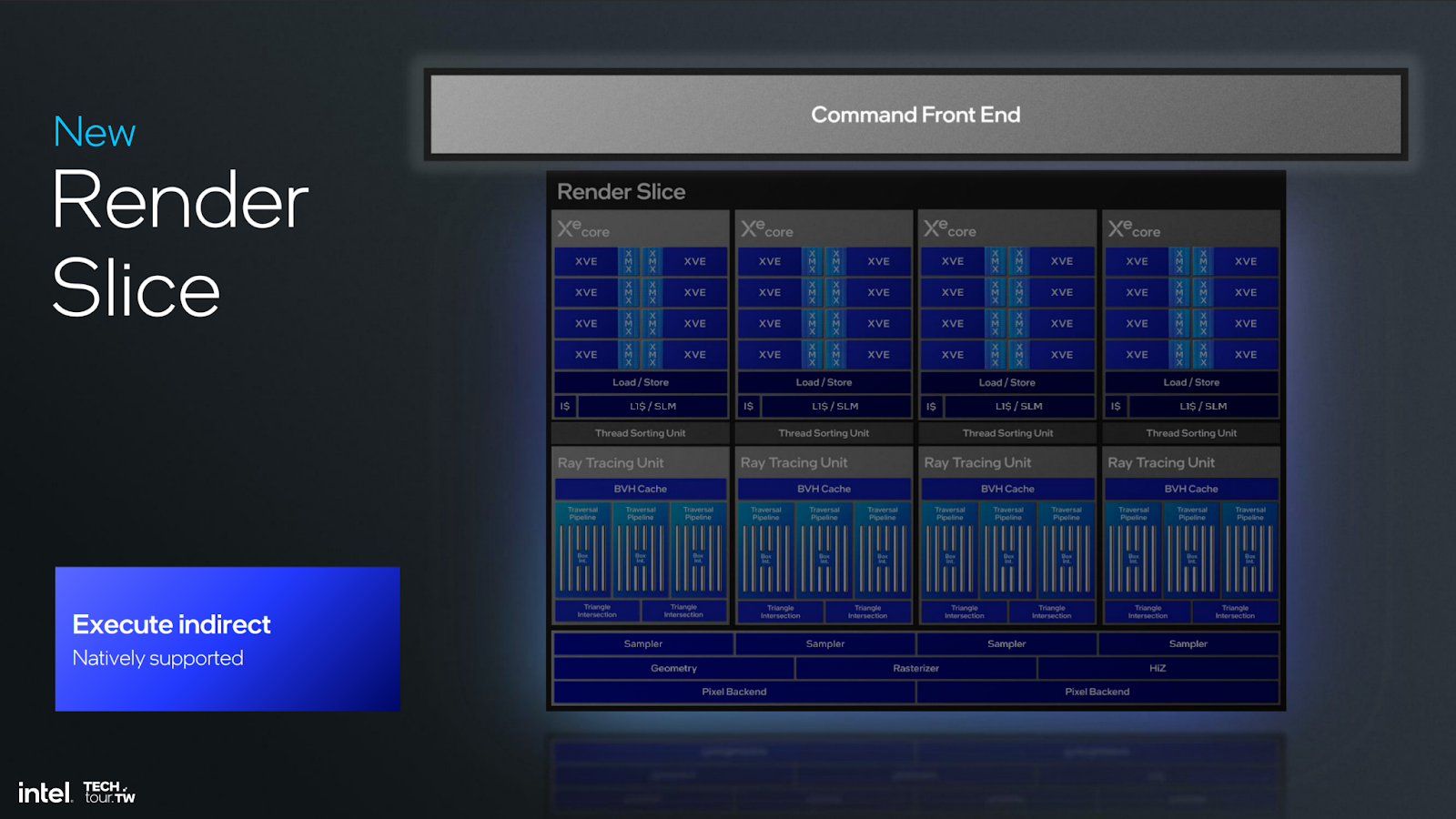
Intel also showed its new Xe2 Render Slice officially for the first time. We’re finally able to start getting a picture for the changes.
Intel’s Tom Petersen presented details to the press highlighting performance efficiency uplift and increased utilization and a reduction in wasted processing in the pipeline. This is where Intel is focusing its efforts for Battlemage.
Alchemist GPUs like the A750 and A770 have a lot more power than they can properly leverage. They use relatively massive dies at a cost that wouldn’t make sense for NVIDIA, for example, to sell. We’ve seen this on the driver side, where Intel’s ability to post massive improvements in performance has proven driver limitations. Intel also made architectural choices that limited Alchemist though, so the key area for improvement is utilization.
Old Alchemist Render Slice
This is a render slice from the original Intel Alchemist architecture. Each render slice is pictured as containing 4 Xe core blocks, each of which itself contains the vector engines, XMX hardware, load/store, and cache hardware. The render slice also contained 4 Ray Tracing Units, samplers, Hi-Z, geometry and rasterization hardware, and a pixel backend.

New Battlemage Render Slice
This is the new Battlemage Render Slice.


One of Intel’s larger changes is re-architecting the GPU to SIMD 16 instead of SIMD 8. SIMD means Single Instruction, Multiple Data. Moving to a native SIMD16 engine was promoted as a key change architecturally. Intel described the change like this:
“Basically, there’s 8 lanes of computation for every instruction. We’ve moved that architecture to be 16 wide, which has a lot of efficiency benefits but also compatibility benefits. More and more often, you’ll see games running right out of the box.”
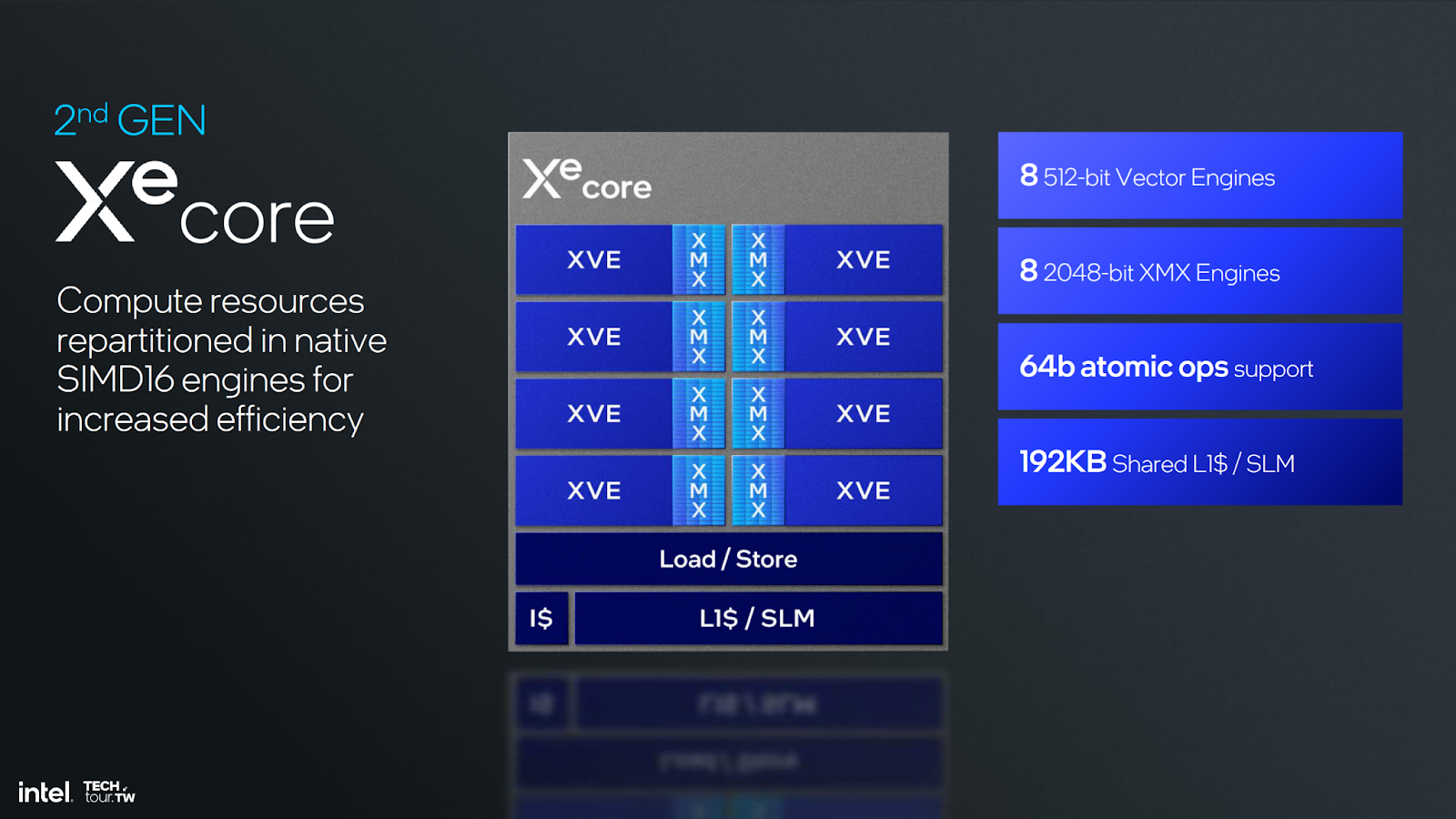
This change also means that Intel’s XVE (or Xe Vector Engine) core count has reduced per Xe Core and render slice. The new Xe core for Gen2 is halved for Vector Engine count per Xe core; however, Intel tells us that this is countered with the increase in width to SIMD16 from SIMD8. We’ll be curious to see if this leads to a reduction in performance anywhere else in the pipeline in any rare scenarios.
But with the claimed upside including better day-one support, if realized, that would rectify a major usability shortcoming of Alchemist. That’s arguably more important than any other aspect of Arc GPUs right now. It’s really what Intel needs in GPUs right now. Our most recent Arc coverage was a nearly two year revisit where we looked at the progress Intel’s Arc drivers made in that time. The conclusion was basically that while yes, it has improved, no, we can’t recommend it still for people who need day one support for the most recent games.
The next big change that Intel highlighted was implementing execute indirect support natively for indirect draw and dispatches, rather than what Intel did on the original Xe (which was emulate it). Intel told us that the 12.5x increase in Draw XI performance shown in the prior chart comes from the native Execute Indirect implementation. Intel stated:
“This is used by engines like Unreal 5 extensively. Having support for this in hardware is a need for next generation games.”
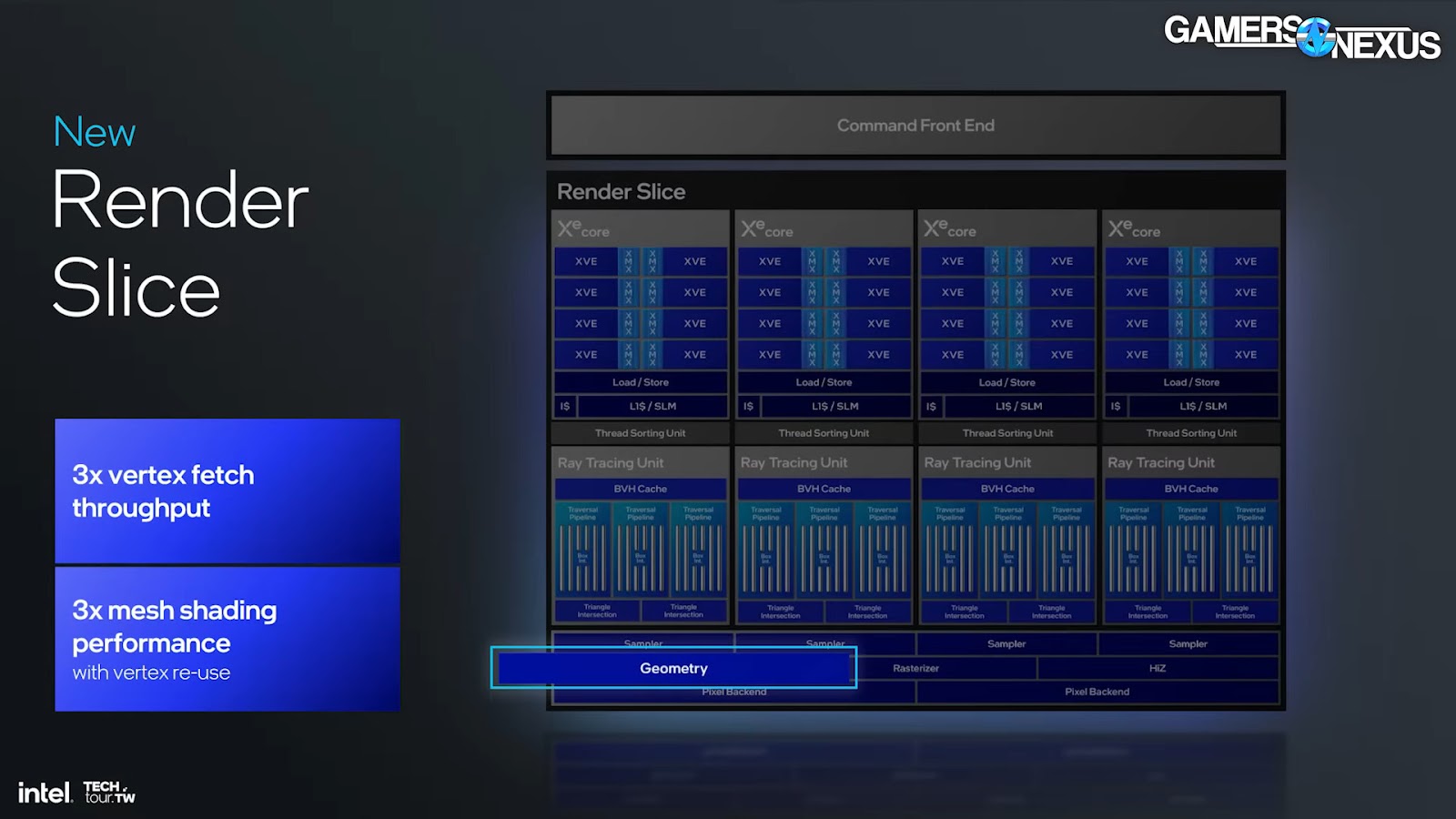
Intel also noted improvements to several other areas. Rapidly, those areas include: the geometry block, mesh shading performance, out-of-order sampling and execution, fetch, Hi-Z and triangle culling, render target prefetch on L2 cache, even clears have been changed, blending, and ray tracing.
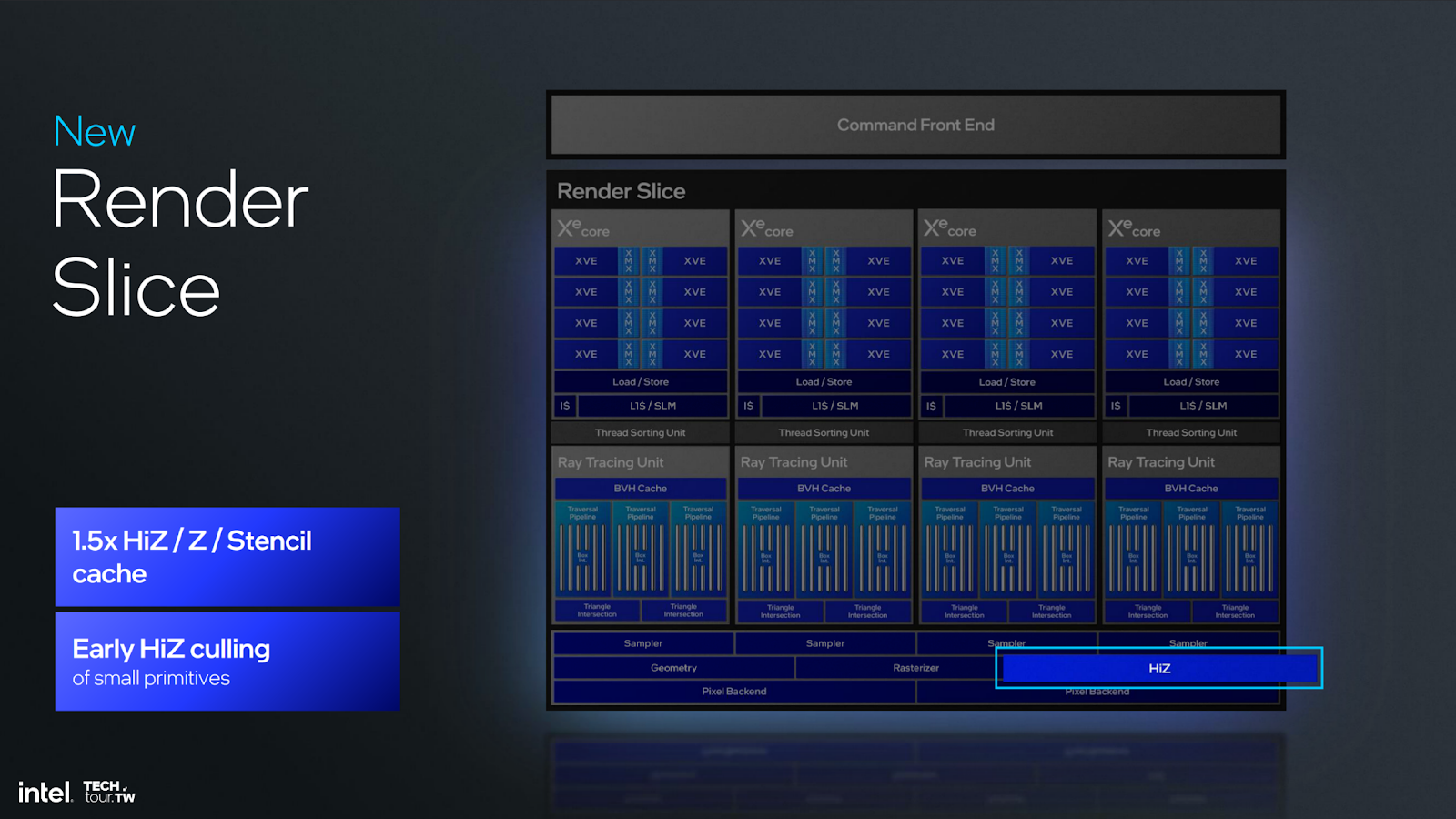
Intel would say that these improvements contribute to greater utilization. Our interpretation of them is that they reduce waste, though. For instance, changing the clear behavior to mark a bit instead of write 0s when starting from scratch on a new frame is an optimization improvement that reduces waste. Changing Hi-Z and culling behavior is also specifically a waste improvement.
Culling isn’t new, but how Intel handles some aspects of it is.
Intel stated this:
“We’ve redone our Hi-Z. If you think about fixed function, it generally starts with reading geometry, then you’re translating geometry using matrix multiply and worldspace. You’re moving these triangles around. Eventually you have to get to a point where you show a pixel. You’re going to convert a triangle to a fragment, which you’re going to shade to draw a pixel. That fragment processing is very important for the order of those triangles in the final scene. [Hi-Z] remembers which triangle is closest. If it ever sees a triangle that’s further away, it will instantly cull it from the pipeline. It’s a trick to reduce pressure on your later shading.”
More aggressively culling triangles or fragments that won’t be seen means, as Tom Petersen said here, later shading processes can focus resources instead on visible components of the scene. The improvement should be lower resource utilization on wasted shading, to instead allow higher performance or more appropriately spent resources on visible parts of the scene.
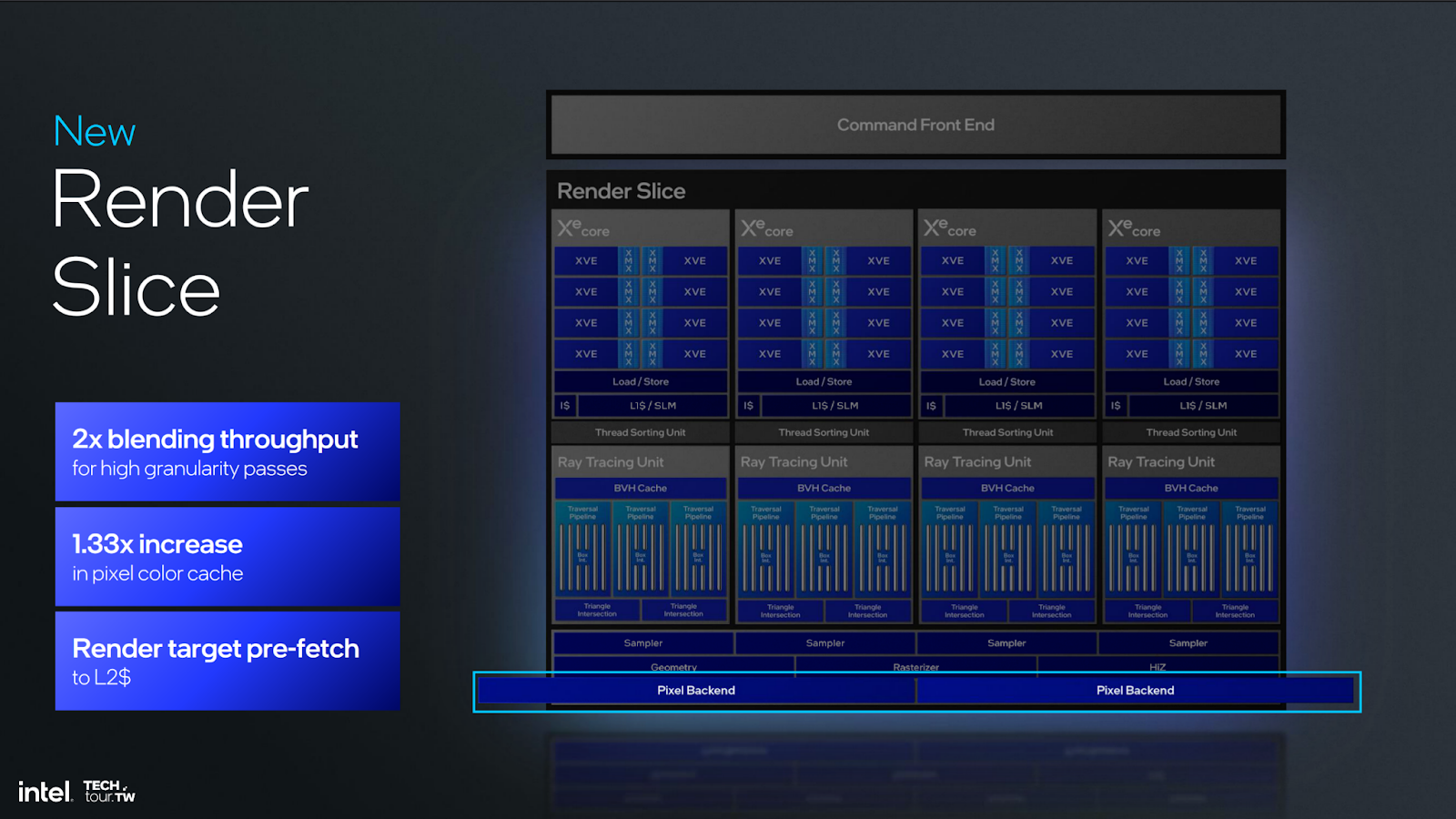
The pixel back-end has also improved, where Intel says it has 2x shading throughput. When there are transparencies in a scene, the GPU has to do math to blend the multiple layers of transparencies. Think about a tinted glass window with a semi-transparency in front of an opaque object like a game character. The GPU will not only draw each of these objects, but also blend the colors of them to accurately represent the filtered color. That’s not new, but Intel has increased bandwidth for shading to improve performance in this part of the pipeline. The company also stated a 33% increase in pixel color cache, reducing bandwidth demand. The reduction in bandwidth is because more data can be resident in cache, reducing transactions out to memory.
Intel also noted geometry pipeline improvements:
“On the geometry block, we’ve improved fetch. We’ve redone how work is distributed to the geometry pipeline to improve utilization by a ton. Mesh shading performance has improved dramatically with vertex re-use. A lot of times, you have a vertex that’s used across multiple triangles, and now we avoid a second fetch. We now support what’s called a stripe. If you think about DirectX, a lot of the time, you have a vertex that’s used across multiple triangles. We now take advantage of that in hardware and avoid a second fetch.”
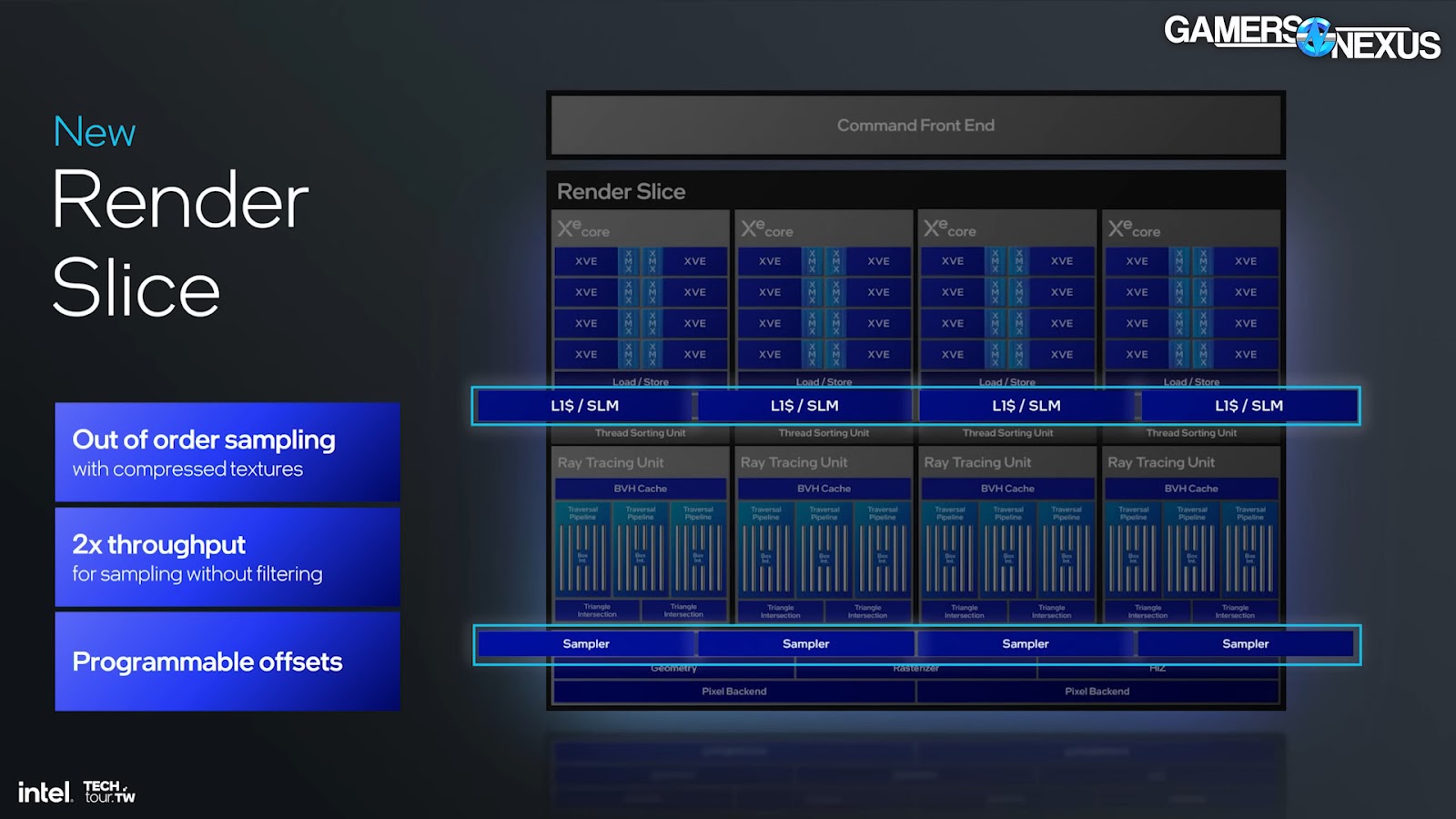
This is another waste reduction. Avoiding a fetch keeps that resource for other transactions. Intel also said that out-of-order sampling improvement is necessary to be able to efficiently fetch compressed textures that reside in cache. Intel’s approach to sampling is to pull large, sometimes multi-gigabyte textures from cache. Intel says that it can fetch these more efficiently now. The company also noted programmable offset support, saying: “We’re talking about an offset relative to the center of the sample, which allows us to implement higher level filters directly in hardware.”
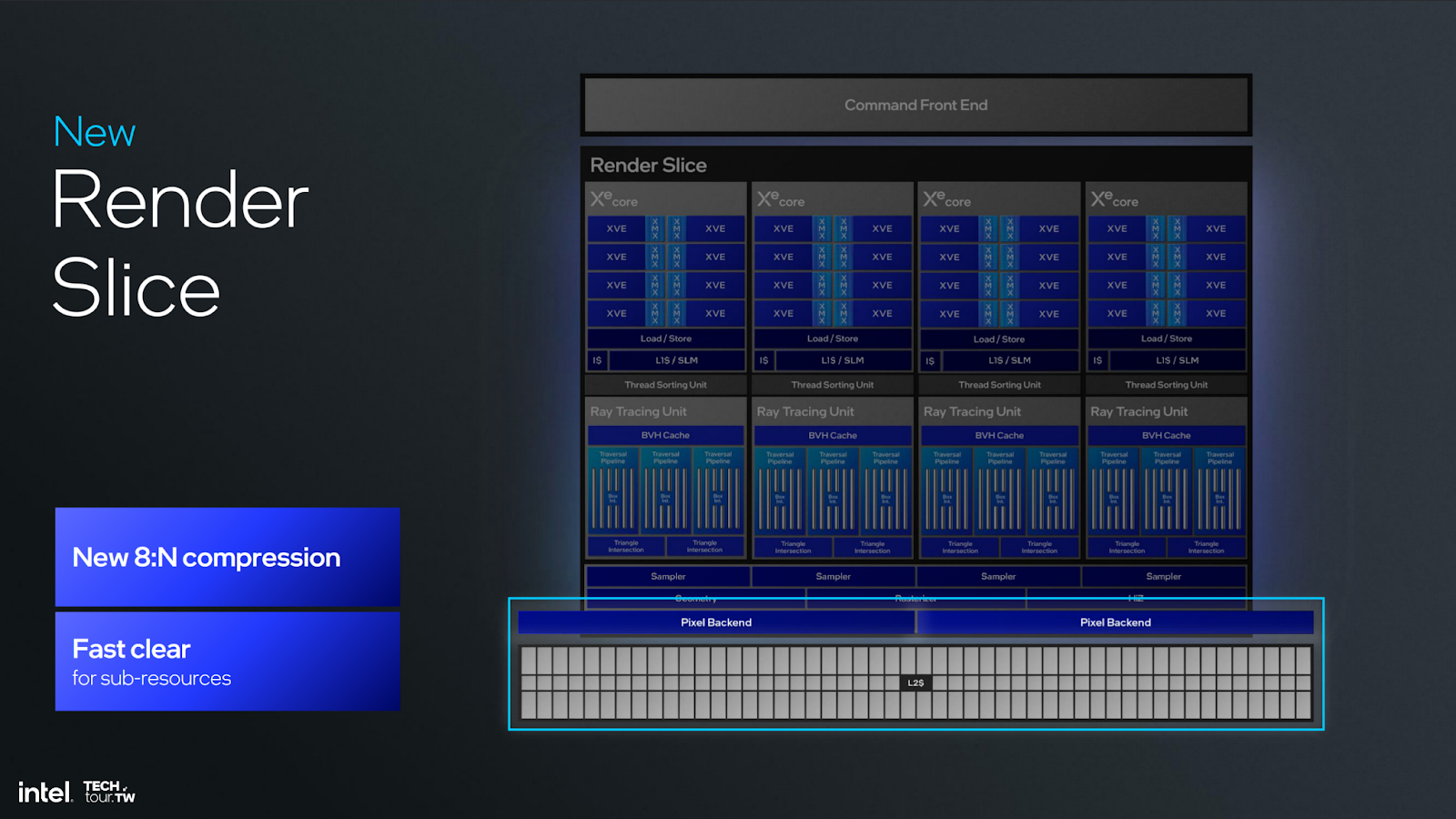
The next big improvement was to the compression algorithm. Intel said it supports a new 8:N compression algorithm on the pixel back-end. This is when it spoke about clear performance as well, noting that the move to mark a bit instead of write zeroes “is a no-brainer but dramatically improves performance.”

On ray tracing, Intel re-explained how bounding volume hierarchies work and then stated that Xe2 is increasing to 3 traversal pipelines, 2 triangle intersections per RT unit, and 18 box intersections per unit. Intel was already doing well in ray tracing relative to AMD and may be able to compete with NVIDIA at least in price-efficient RT.

There was a lot more discussion about Xe2 as it relates specifically to Lunar Lake, but all the stuff we’ve talked about so far applies to all Xe2 implementations. That means Battlemage and Lunar Lake both benefit from these changes. We’ll leave out the Lunar Lake-specific GPU discussion for today, as processing and condensing all of this information abroad is already intensive on the schedule. Let’s move on to the announced core architecture changes for Lunar Lake. Some of these apply to Intel’s future Arrow Lake for desktop as well. We’re hearing rumors that will be in the Fall of this year.

Lunar Lake P-cores “Lion Cove” – No More Hyper-Threading
Intel gave us a technical deep dive on its new P-core and E-core microarchitectures. This time, it’s all about efficiency and IPC. The biggest news is that Intel has dropped SMT, or Hyper-Threading, from the design entirely. We’ll start with that and the new P-cores.
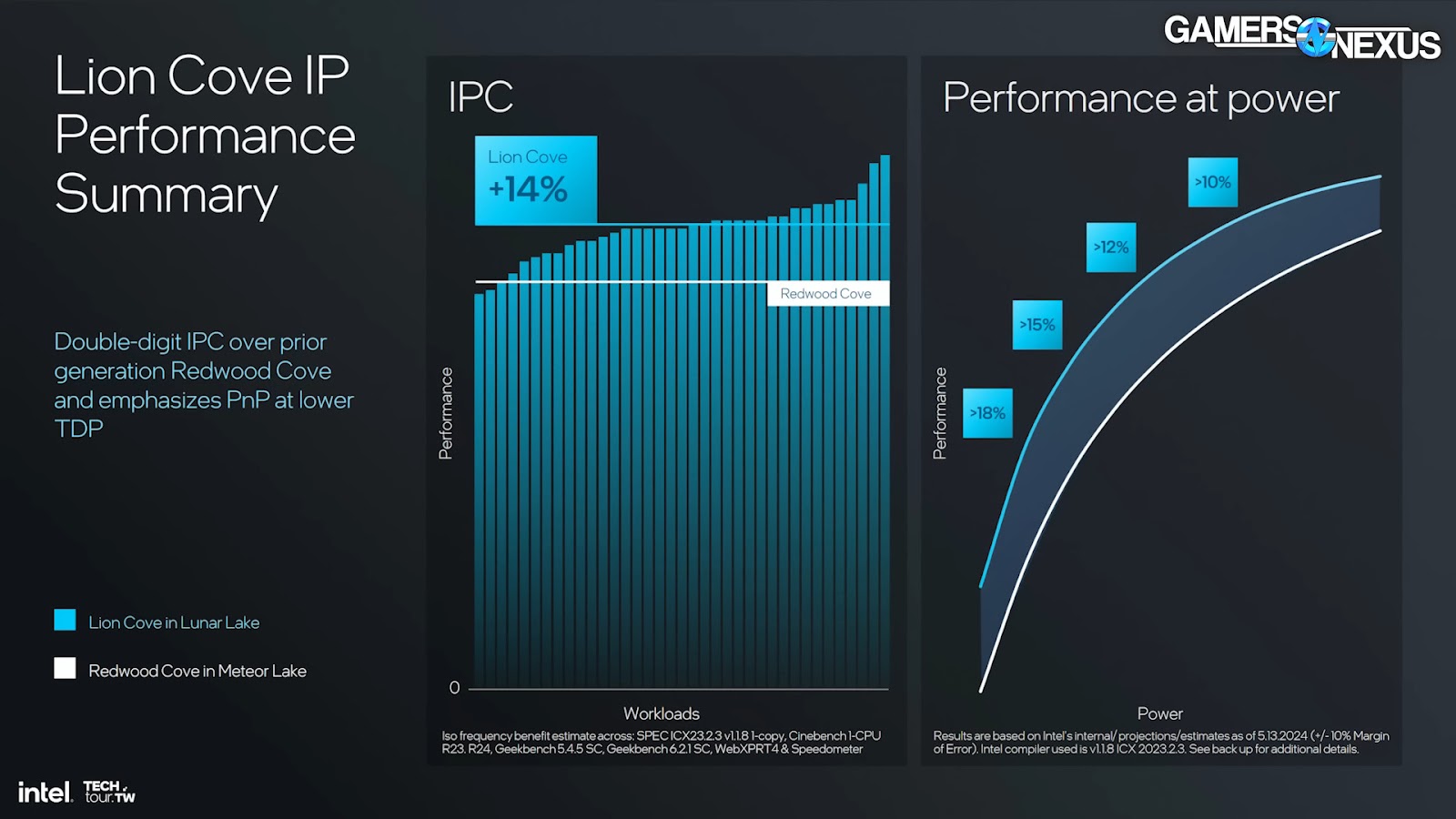
“Lion Cove” P-cores will show up first in Lunar Lake mobile CPUs and are a microarchitectural overhaul that include fundamental design changes that should allow for better scaling into future generations.
Intel refactored its internal CPU design process and core architecture IP, which it says will continue to give benefits across multiple generations and markets:
Intel said:
"Our new development environment allows us to insert knobs into our design to quickly productize SoC derivatives out of our baseline superset P-core IP, and indeed the Lion Cove version that goes into Lunar Lake is different in several aspects than that which will go into Arrow Lake later this year."
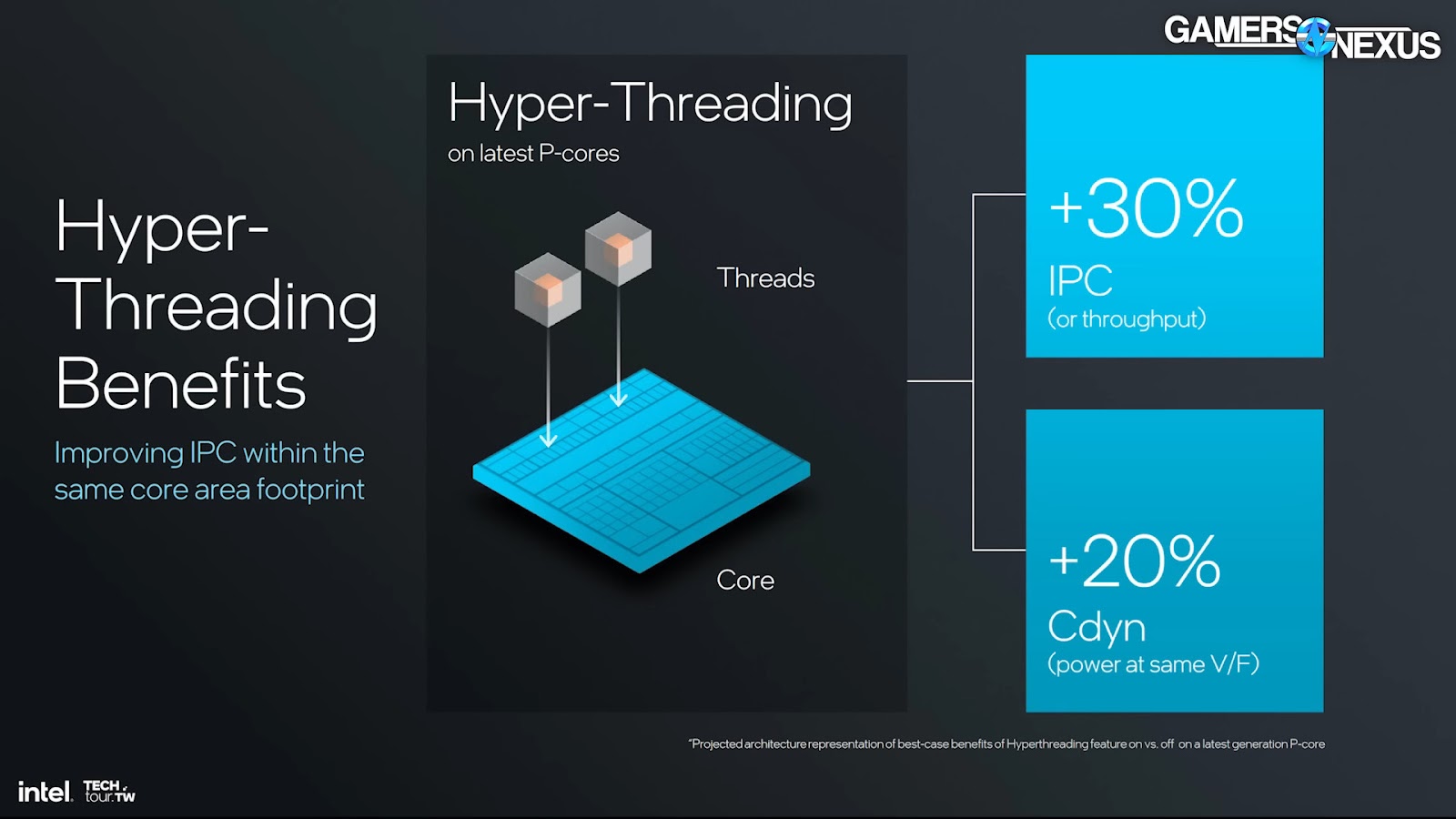
Getting back to the removal of Hyper-Threading, Intel says that in general, Hyper-Threading gains roughly 30% IPC in the same core area footprint – that’s why it’s been used for about 20 years now. It’s not free, though. Intel says that Hyper-Threading necessitates duplication of many architectural elements. Filling the pipeline with multiple threads requires hardware to track the execution into the pipeline and the state of those processes. This takes area and power to accomplish.
Intel gave some numbers to better understand trade-offs at play here. The performance comparisons we’re about to talk about are between the same core architecture if it were hypothetically built with and without Hyper-Threading.

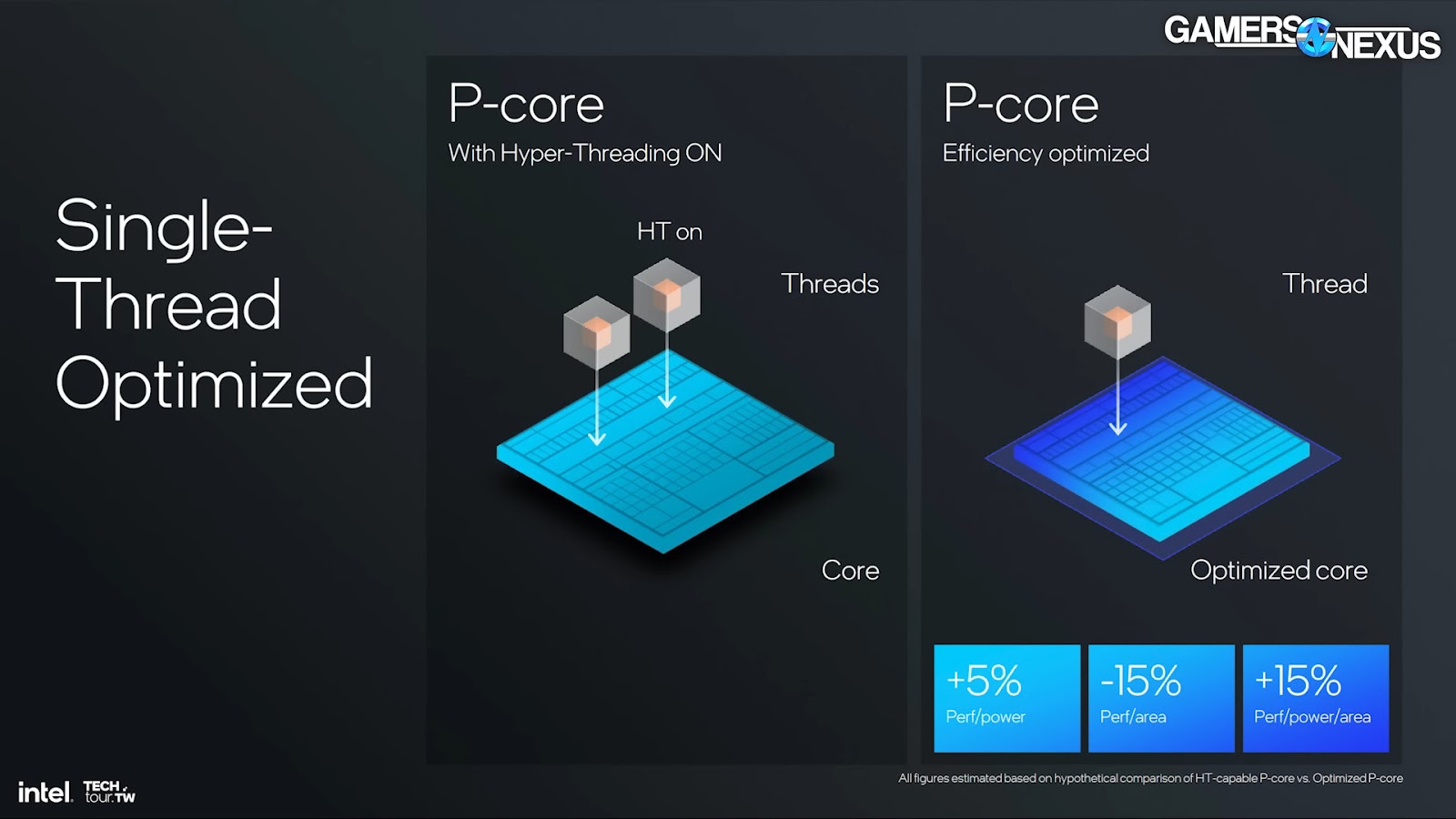
The new efficiency optimized P-cores without Hyper-Threading give 15% better performance per watt and 10% better performance per area as compared to a P-core built with Hyper-Threading, but with it turned off. Then with Hyper-Threading on, the new optimized core built without Hyper-Threading still wins by 5% in performance per watt, but falls behind by 15% in performance per area. That loss is where the new E-cores come in, which we’ll get to shortly. Platforms that purely consist of P-cores would still benefit from Hyper-Threading.
Intel also has updated thermal and power controls. Thermally, the predetermined static guidelines are gone, and are replaced with an “AI self-tuning controller” that does active monitoring and adapts to the specific workload being run.

Intel is also adding finer grain clock control, at 16.67MHz clock intervals. Intel gave the example of a workload where the max theoretical clock was 3.08GHz – Intel’s previous 100MHz steps would have the core cap out at 3.0GHz, but the new 16.67MHz steps would allow for a 2% higher clock of 3.067GHz. On the flip side, this also gives better control in power-constrained situations, like a laptop. The end result should be higher sustained clock speeds for given power budgets and thermal constraints anywhere on the curve.


Other improvements include a much larger instruction prediction block, larger operation cache, and deeper operation queue. Vector and integer operations are now in separate pipelines with separate schedulers for out of order execution.

Updates to the memory subsystem include lowering the latency of the nearest L0 cache, and adding an intermediate L1 cache to create a 3-level hierarchy. Total per-core cache capacity is slightly up overall.
Some quick notes: Intel claims an average of 14% more performance at the same frequency for one P-core versus Meteor Lake cores. Perf per watt ranges between 18% more at the low end of power to 10% more at the higher end versus Meteor Lake.
Once these updated P-cores make their way to the desktop platform, we’ll thoroughly benchmark how they perform in Arrow Lake.
Lunar Lake E-cores “Skymont”
Moving on to Intel’s updated “Skymont” E-cores for Lunar Lake, the biggest change coming from the previous generation is upping the count from 2 to 4 cores per cluster. With the removal of Hyper-Threading on the P-cores, Intel is betting that its new E-cores are good enough to pick up the slack on multi-threaded workloads.
“Our E-Cores are getting so good that we can deliver better than SMT (or better than Hyper-Threading) performance, without Hyper-Threading. That is the key motivation for making the P-core wider and extracting more performance out of every MHz.”



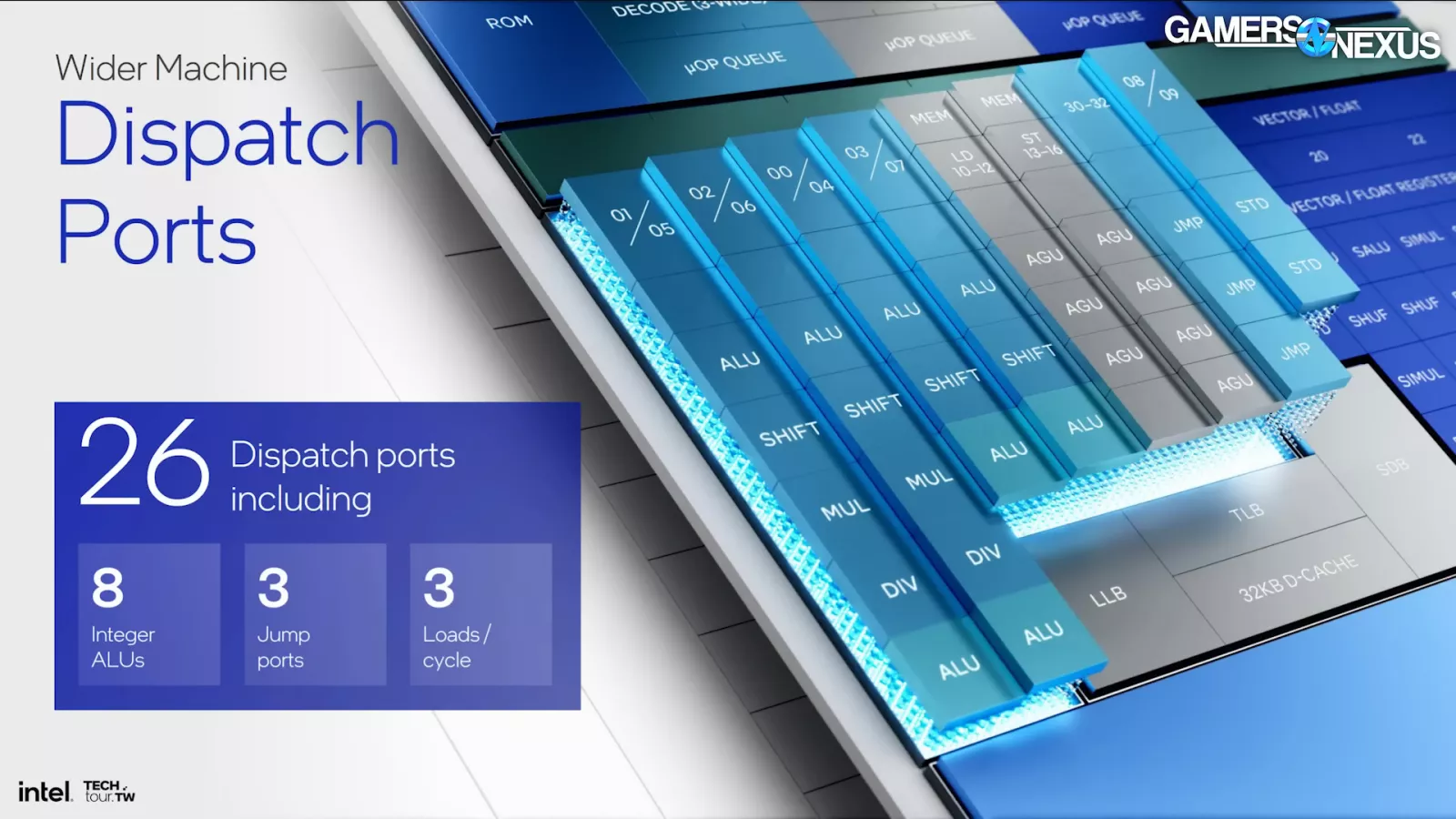

The updates to the individual cores themselves are similar to the changes to P-cores. Instruction caches are larger and queues are deeper. The core is much wider in general, with vector capability being roughly doubled. Intel says vector is generally the type of compute that AI leverages.

The E-core memory subsystem was also updated. There’s also more cache available overall, with 4MB of shared L2 between each 4-core cluster, with double the bandwidth compared to the previous generation.
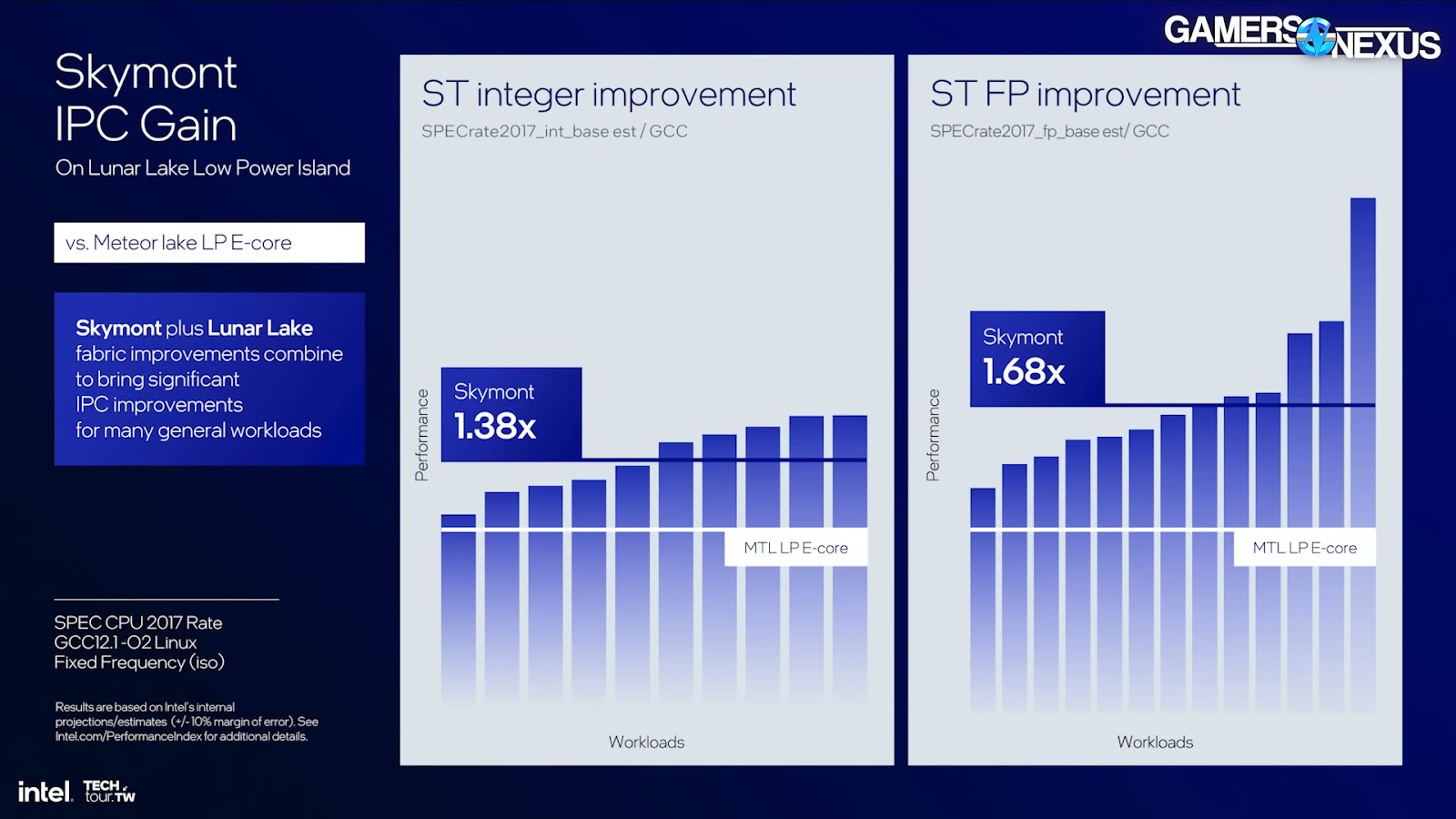
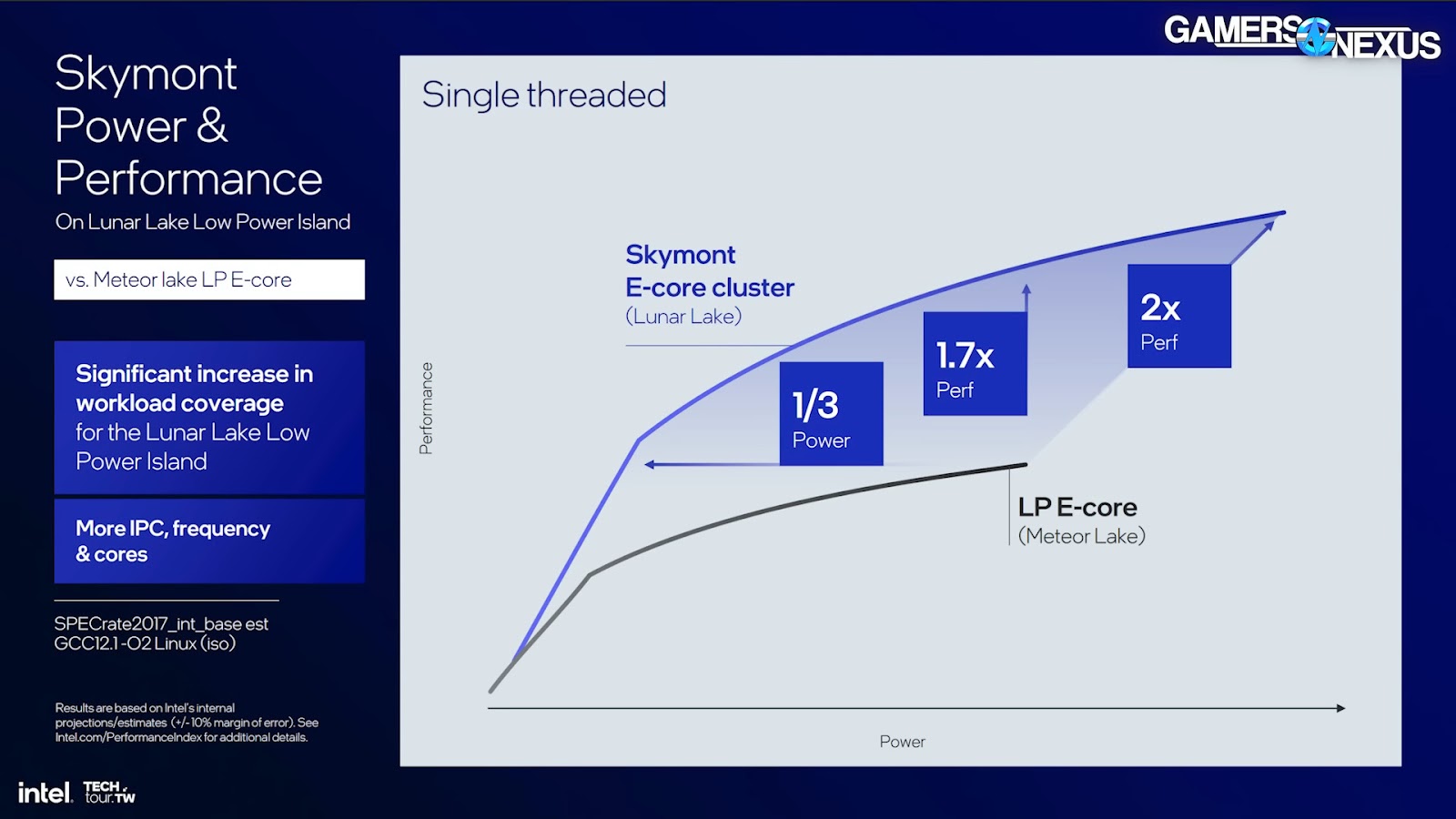
For performance, Intel gave some single threaded performance numbers between the “Low Power Islands” of the previous generation Meteor Lake and new Lunar Lake mobile CPUs. Integer functions were up by an average of 38%, and floating point (vector) is up by 68% claimed on average, though Intel’s graph has one high outlier. Overall in a single threaded scenario, Intel says the new E-core uses 1/3 the power at the same performance, 1.7x more performance at the same power, and 2x the performance at the top end with the new core using more power.
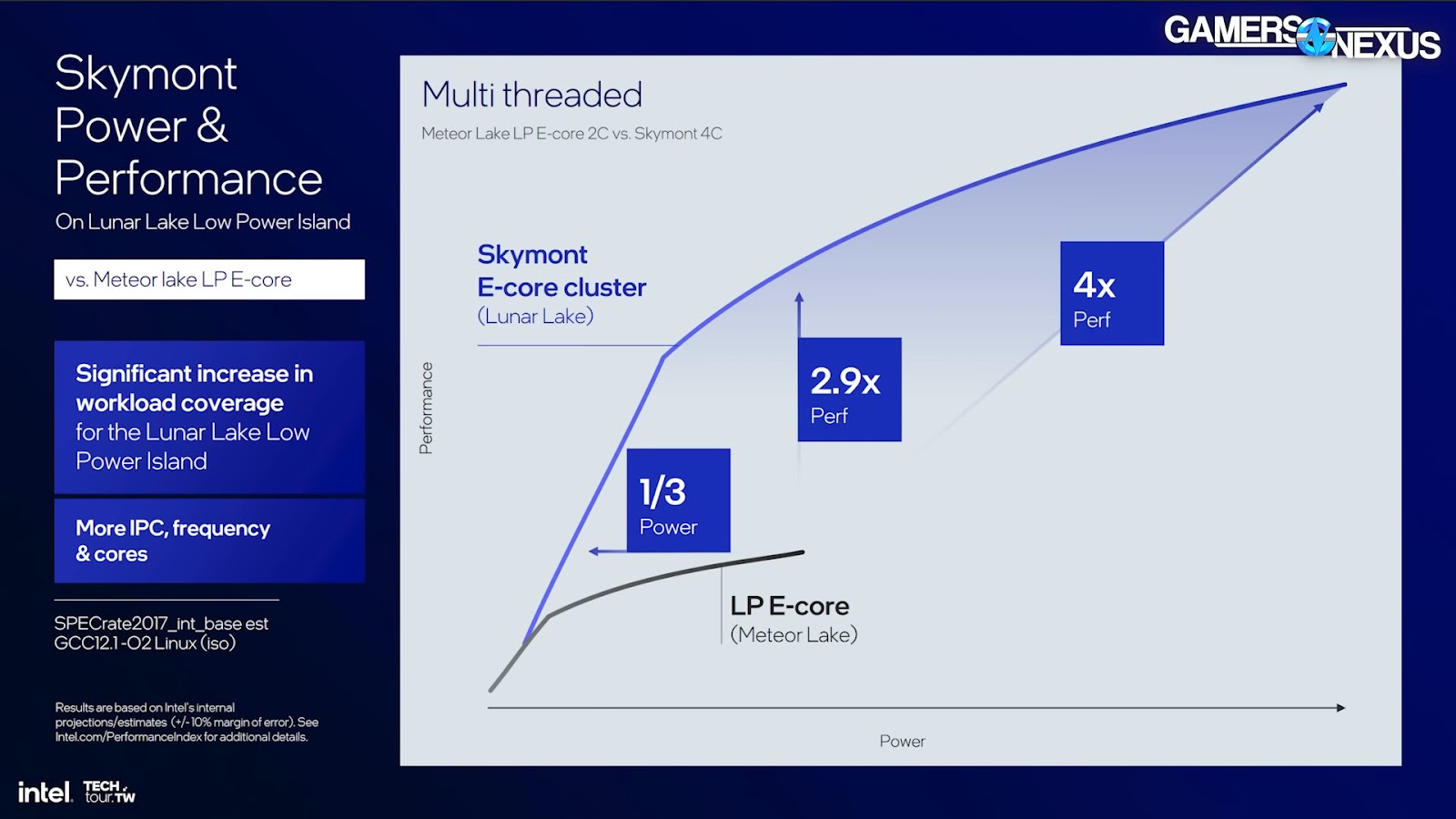
Moving to multi-thread, Intel says total performance uplift on the Low Power Island is heavily increased due to both the cores being faster and the increase from 2 to 4 E-cores per cluster. Integer performance is again 1/3 the power at the same performance, 2.9x more performance at the same power, and 4x more performance at the top end using much more power.
Intel also gave an interesting performance comparison for the desktop, where it put the new Skymont E-core against the outgoing Raptor Cove P-core. This is inherently an uneven comparison since P-cores scale higher with higher power and frequency, but the bottom half of the curve is interesting.
There were a number of other improvements as well, like bottom-up scheduling and thread director changes. We’ll probably talk more about this once the desktop solutions start shipping.
